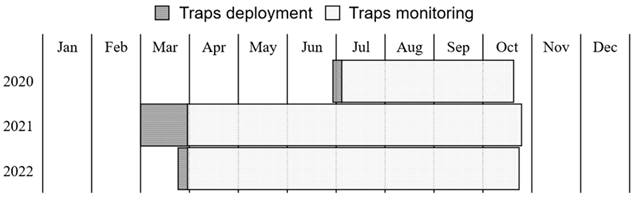
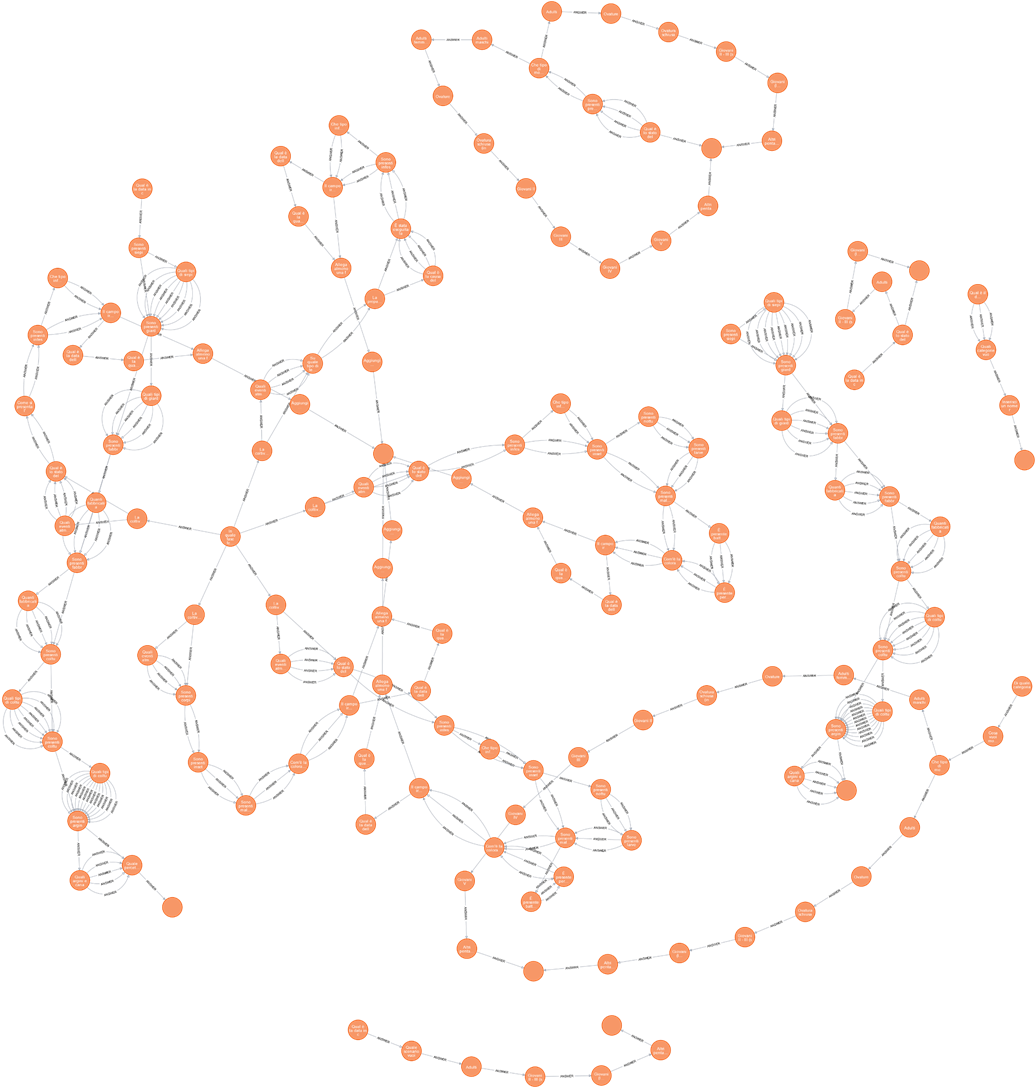
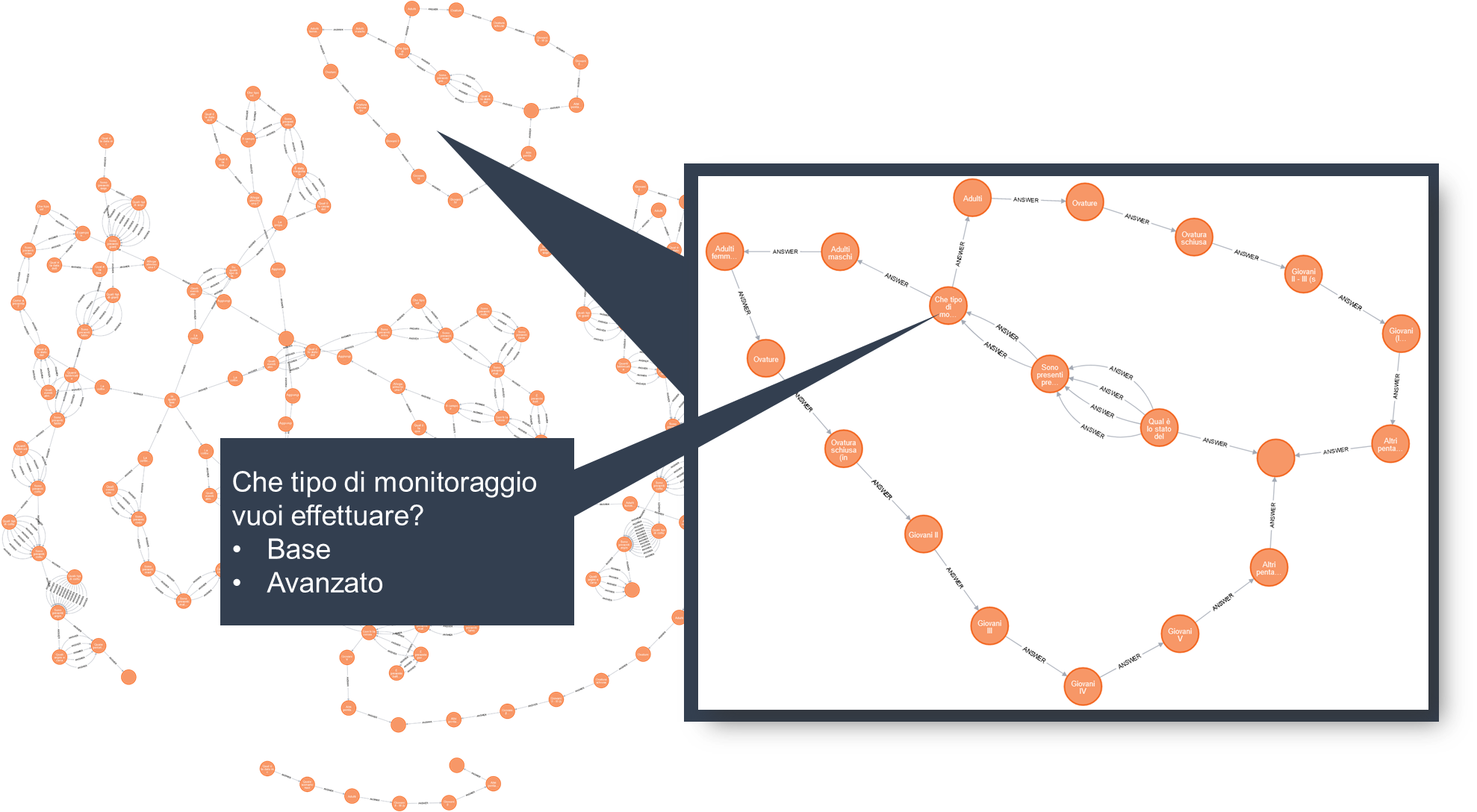
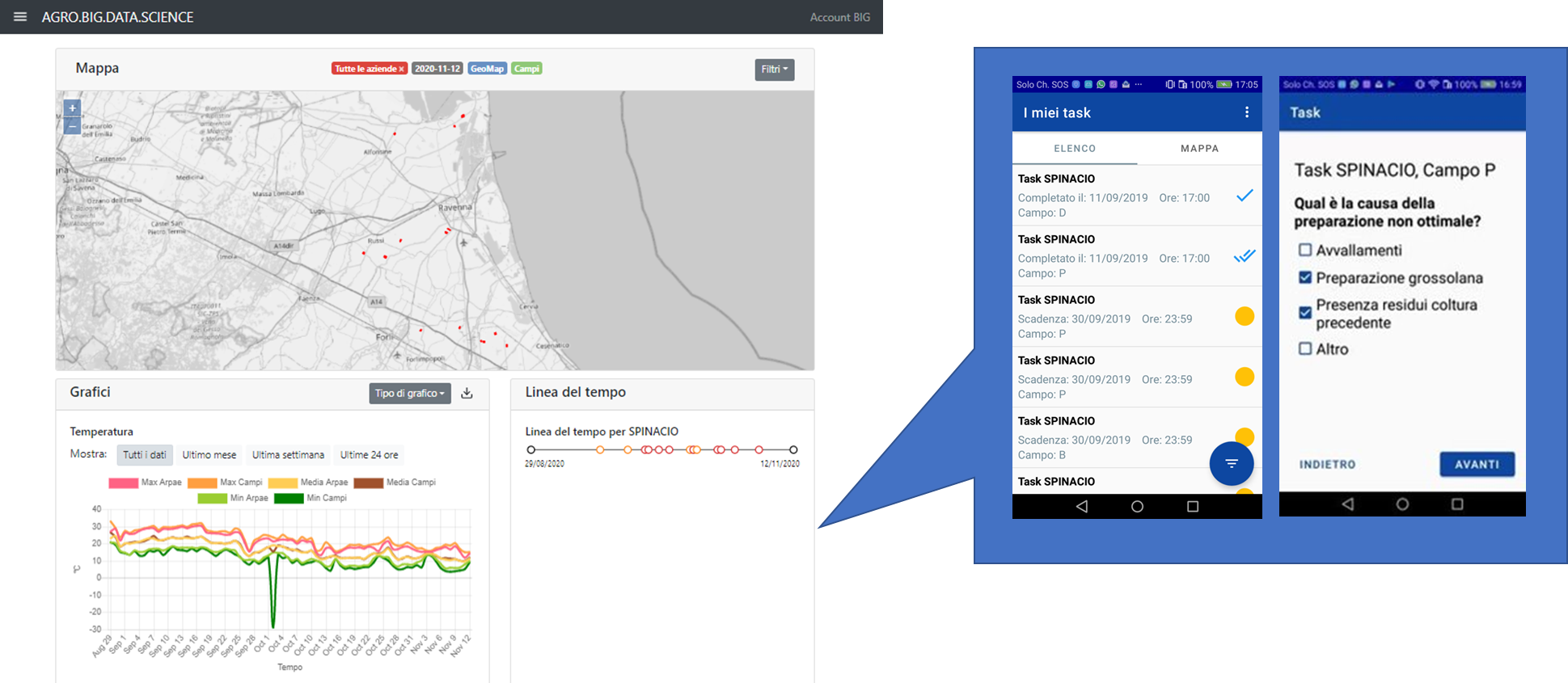
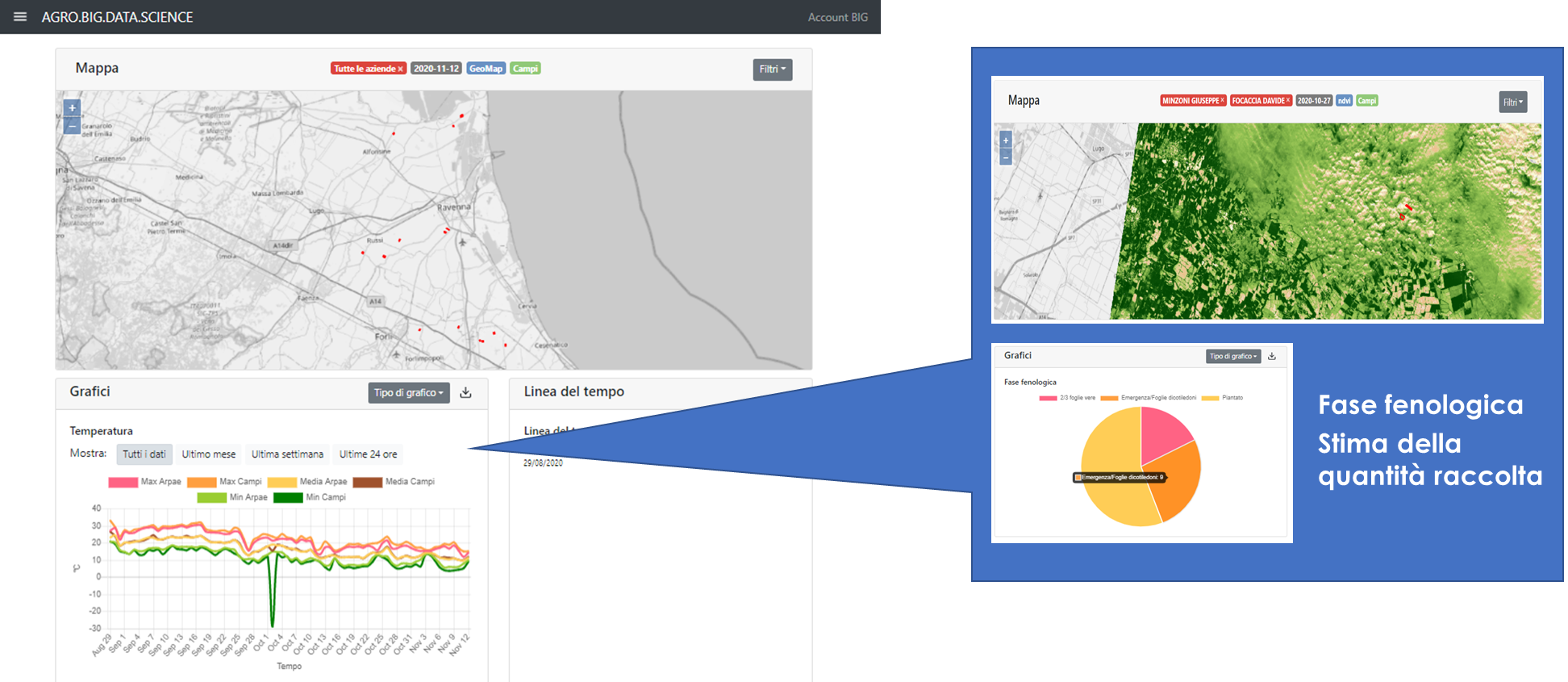
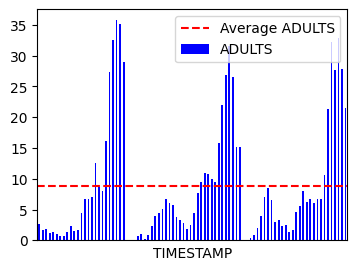
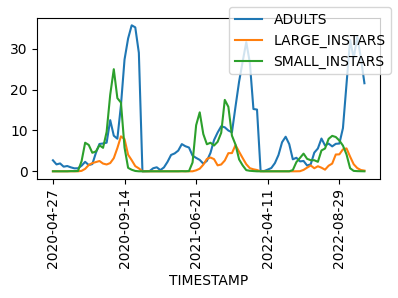
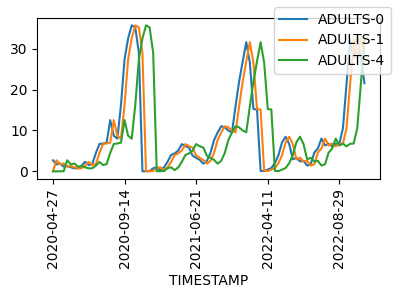
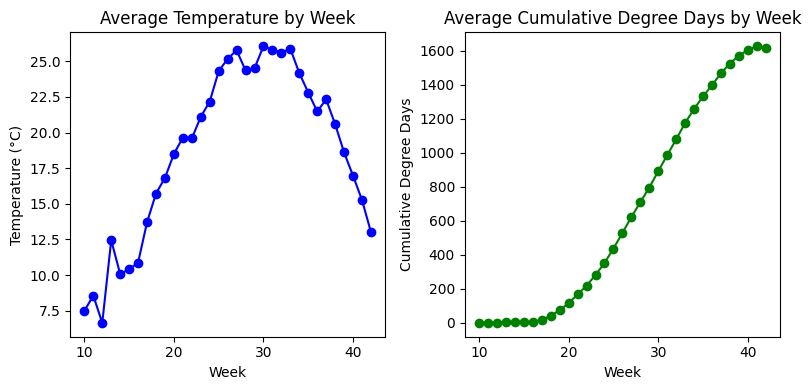
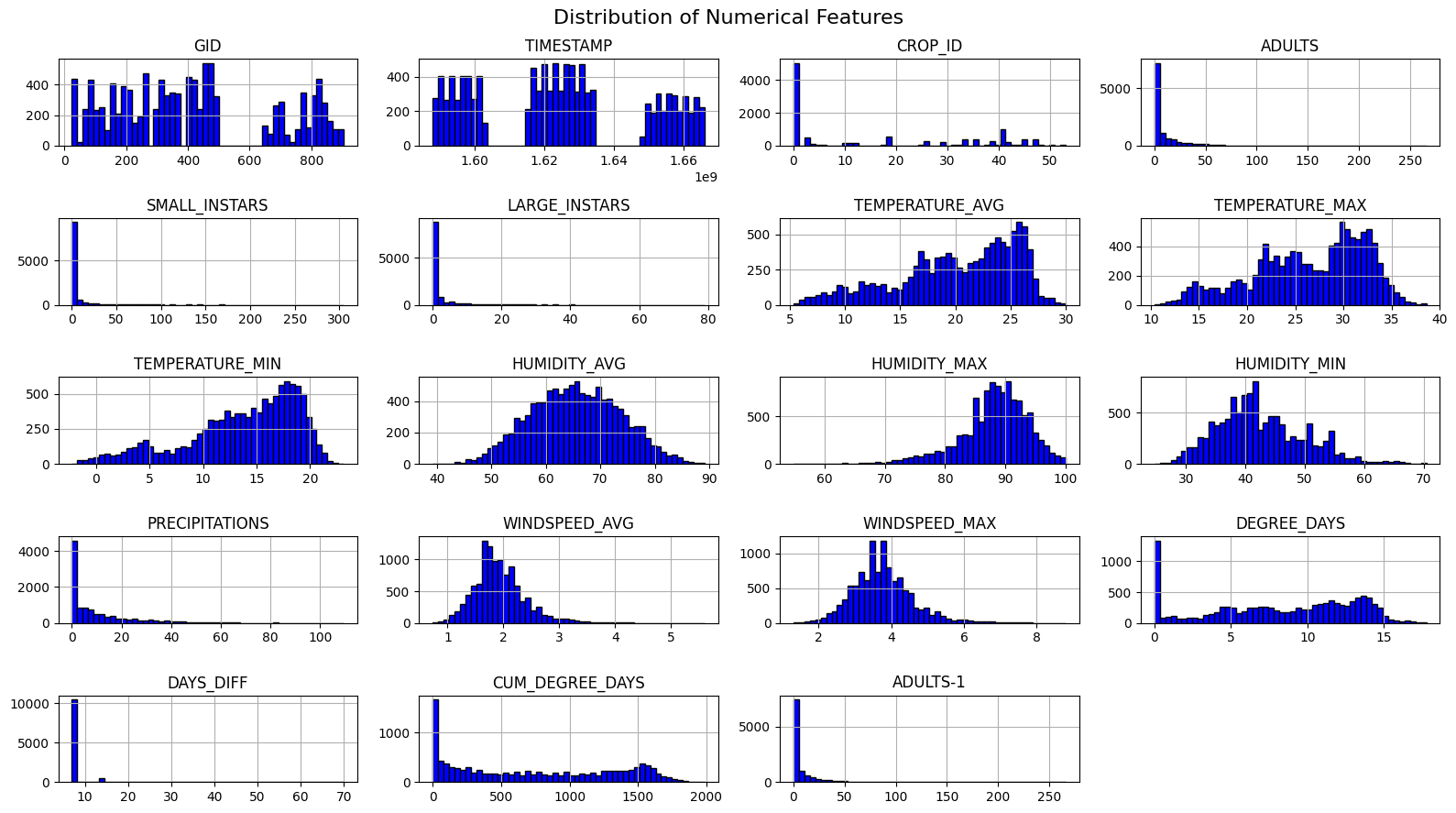
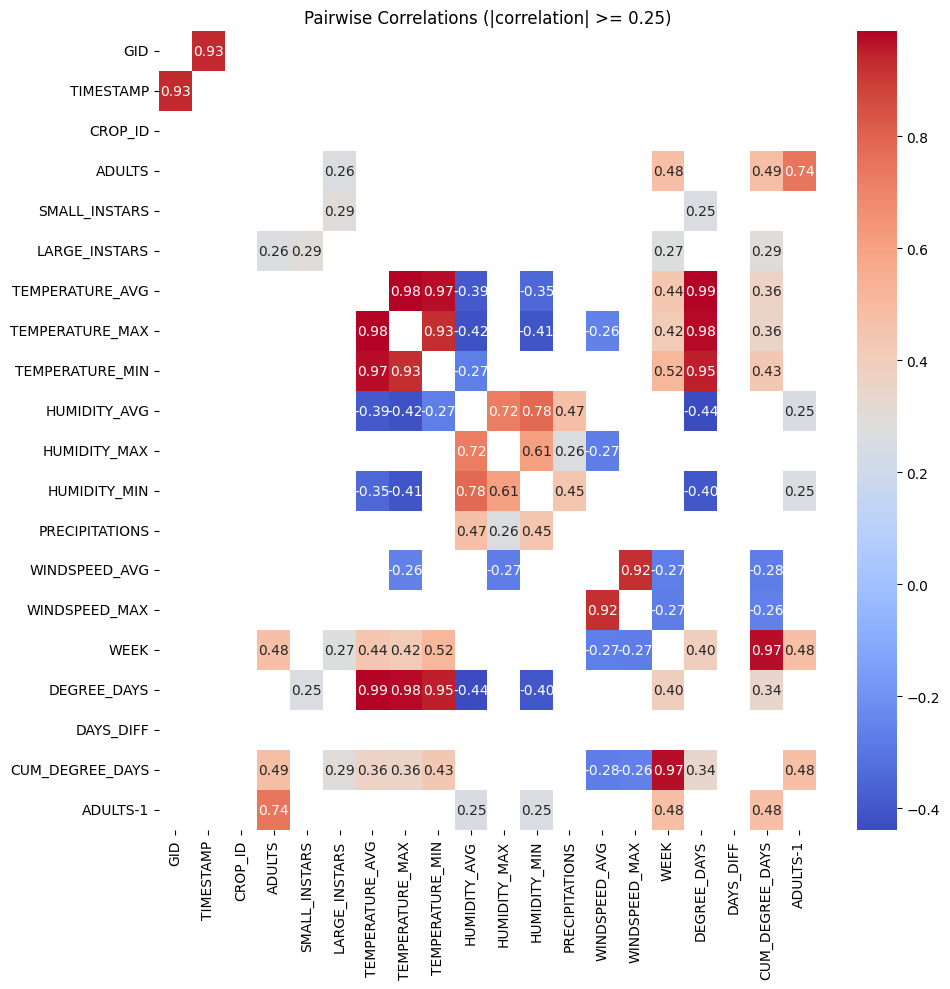
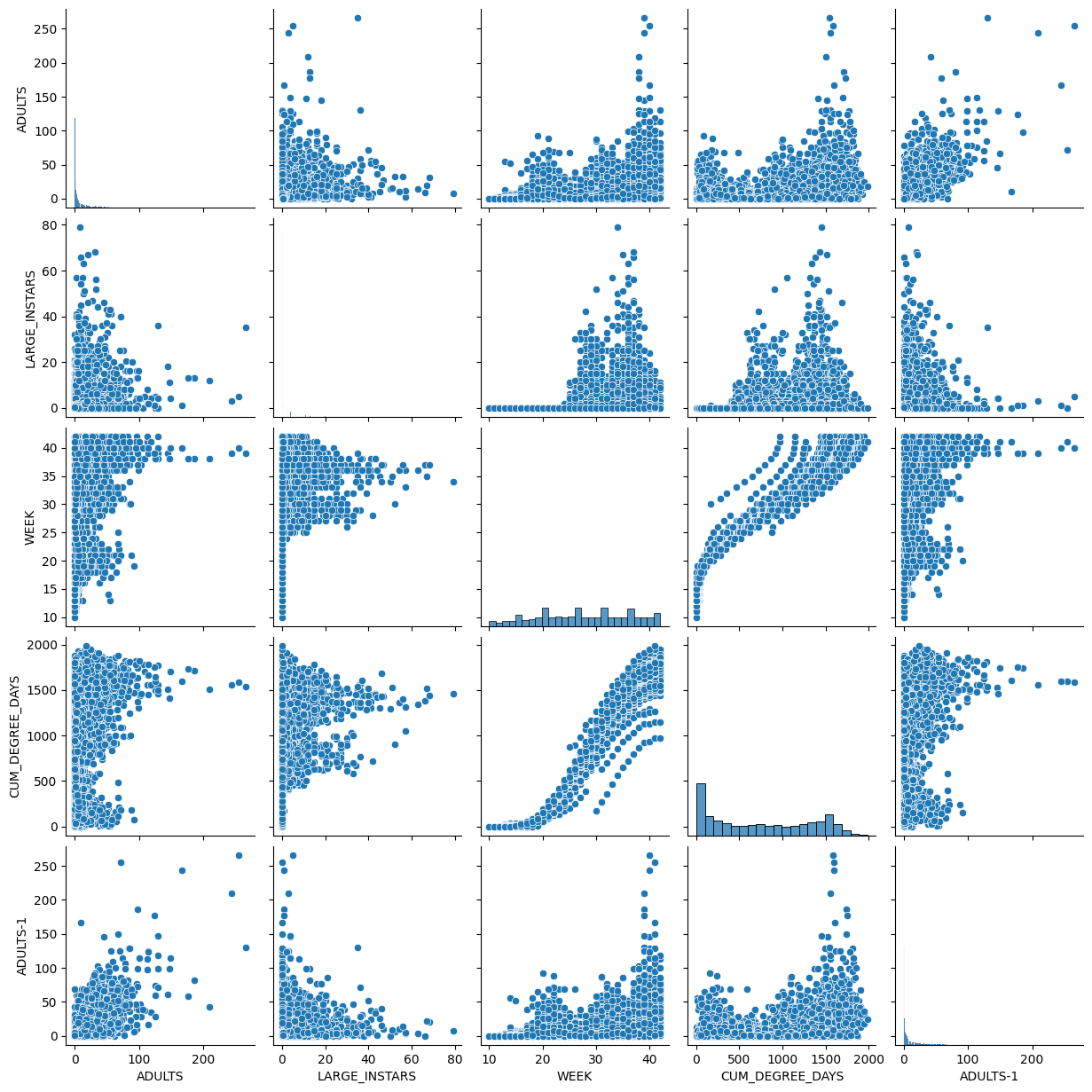
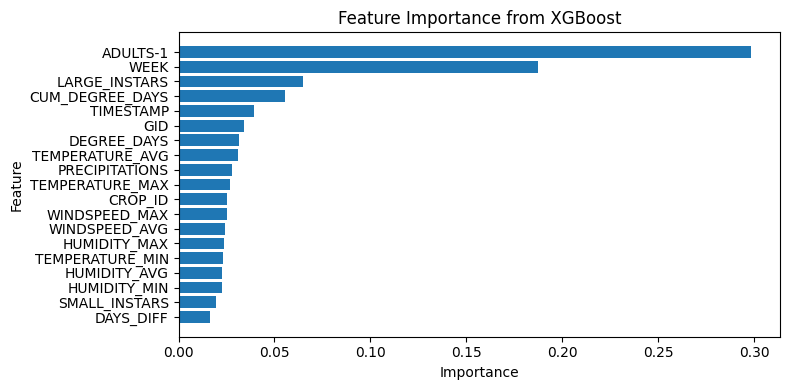
Fitting 5 folds for each of 30 candidates, totalling 150 fits
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.01, max_depth=3, min_child_weight=3, n_estimators=100, subsample=1.0; total time= 0.6s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.01, max_depth=3, min_child_weight=3, n_estimators=100, subsample=1.0; total time= 0.7s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.01, max_depth=3, min_child_weight=3, n_estimators=100, subsample=1.0; total time= 0.6s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.01, max_depth=3, min_child_weight=3, n_estimators=100, subsample=1.0; total time= 0.6s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.01, max_depth=3, min_child_weight=3, n_estimators=100, subsample=1.0; total time= 0.6s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.01, max_depth=5, min_child_weight=7, n_estimators=300, subsample=1.0; total time= 2.3s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.01, max_depth=5, min_child_weight=7, n_estimators=300, subsample=1.0; total time= 2.3s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.01, max_depth=5, min_child_weight=7, n_estimators=300, subsample=1.0; total time= 2.7s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.2, max_depth=3, min_child_weight=1, n_estimators=300, subsample=0.8; total time= 1.6s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.2, max_depth=3, min_child_weight=1, n_estimators=300, subsample=0.8; total time= 1.4s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.2, max_depth=3, min_child_weight=1, n_estimators=300, subsample=0.8; total time= 1.4s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.2, max_depth=3, min_child_weight=1, n_estimators=300, subsample=0.8; total time= 1.5s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.2, max_depth=3, min_child_weight=1, n_estimators=300, subsample=0.8; total time= 1.6s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.01, max_depth=5, min_child_weight=7, n_estimators=300, subsample=1.0; total time= 4.9s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.01, max_depth=5, min_child_weight=7, n_estimators=300, subsample=1.0; total time= 5.0s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.01, max_depth=7, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 5.4s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.01, max_depth=7, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 5.7s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.01, max_depth=7, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 2.5s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.01, max_depth=7, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 2.3s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.01, max_depth=7, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 4.3s
[CV] END colsample_bytree=0.6, gamma=0, learning_rate=0.1, max_depth=5, min_child_weight=5, n_estimators=500, subsample=0.8; total time= 2.5s
[CV] END colsample_bytree=0.6, gamma=0, learning_rate=0.1, max_depth=5, min_child_weight=5, n_estimators=500, subsample=0.8; total time= 3.8s
[CV] END colsample_bytree=1.0, gamma=0.1, learning_rate=0.05, max_depth=10, min_child_weight=3, n_estimators=500, subsample=0.8; total time= 20.1s
[CV] END colsample_bytree=1.0, gamma=0.1, learning_rate=0.05, max_depth=10, min_child_weight=3, n_estimators=500, subsample=0.8; total time= 20.9s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.05, max_depth=10, min_child_weight=3, n_estimators=500, subsample=0.8; total time= 17.5s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.05, max_depth=10, min_child_weight=3, n_estimators=500, subsample=0.8; total time= 18.2s
[CV] END colsample_bytree=0.6, gamma=0, learning_rate=0.1, max_depth=5, min_child_weight=5, n_estimators=500, subsample=0.8; total time= 3.8s
[CV] END colsample_bytree=1.0, gamma=0.1, learning_rate=0.05, max_depth=10, min_child_weight=3, n_estimators=500, subsample=0.8; total time= 22.7s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.05, max_depth=10, min_child_weight=3, n_estimators=500, subsample=0.8; total time= 19.1s
[CV] END colsample_bytree=0.8, gamma=0.1, learning_rate=0.2, max_depth=3, min_child_weight=1, n_estimators=500, subsample=0.8; total time= 2.3s
[CV] END colsample_bytree=0.6, gamma=0, learning_rate=0.1, max_depth=5, min_child_weight=5, n_estimators=500, subsample=0.8; total time= 4.0s
[CV] END colsample_bytree=0.8, gamma=0.1, learning_rate=0.2, max_depth=3, min_child_weight=1, n_estimators=500, subsample=0.8; total time= 2.3s
[CV] END colsample_bytree=0.6, gamma=0, learning_rate=0.1, max_depth=5, min_child_weight=5, n_estimators=500, subsample=0.8; total time= 3.4s
[CV] END colsample_bytree=0.8, gamma=0.1, learning_rate=0.2, max_depth=3, min_child_weight=1, n_estimators=500, subsample=0.8; total time= 2.3s
[CV] END colsample_bytree=0.8, gamma=0.1, learning_rate=0.2, max_depth=3, min_child_weight=1, n_estimators=500, subsample=0.8; total time= 2.3s
[CV] END colsample_bytree=1.0, gamma=0.1, learning_rate=0.05, max_depth=10, min_child_weight=3, n_estimators=500, subsample=0.8; total time= 24.1s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.05, max_depth=3, min_child_weight=1, n_estimators=500, subsample=0.8; total time= 2.3s
[CV] END colsample_bytree=0.8, gamma=0.1, learning_rate=0.2, max_depth=3, min_child_weight=1, n_estimators=500, subsample=0.8; total time= 2.4s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.05, max_depth=10, min_child_weight=3, n_estimators=500, subsample=0.8; total time= 20.8s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.05, max_depth=3, min_child_weight=1, n_estimators=500, subsample=0.8; total time= 2.3s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.05, max_depth=3, min_child_weight=1, n_estimators=500, subsample=0.8; total time= 2.2s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.05, max_depth=3, min_child_weight=1, n_estimators=500, subsample=0.8; total time= 2.3s
[CV] END colsample_bytree=1.0, gamma=0.2, learning_rate=0.2, max_depth=5, min_child_weight=3, n_estimators=300, subsample=0.6; total time= 2.9s
[CV] END colsample_bytree=1.0, gamma=0.2, learning_rate=0.2, max_depth=5, min_child_weight=3, n_estimators=300, subsample=0.6; total time= 2.8s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.05, max_depth=3, min_child_weight=1, n_estimators=500, subsample=0.8; total time= 3.8s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.01, max_depth=3, min_child_weight=1, n_estimators=100, subsample=0.8; total time= 0.7s
[CV] END colsample_bytree=0.8, gamma=0.5, learning_rate=0.05, max_depth=10, min_child_weight=3, n_estimators=500, subsample=0.8; total time= 24.0s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.01, max_depth=3, min_child_weight=1, n_estimators=100, subsample=0.8; total time= 0.9s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.01, max_depth=3, min_child_weight=1, n_estimators=100, subsample=0.8; total time= 0.6s
[CV] END colsample_bytree=1.0, gamma=0.2, learning_rate=0.2, max_depth=5, min_child_weight=3, n_estimators=300, subsample=0.6; total time= 3.0s
[CV] END colsample_bytree=1.0, gamma=0.2, learning_rate=0.2, max_depth=5, min_child_weight=3, n_estimators=300, subsample=0.6; total time= 3.0s
[CV] END colsample_bytree=1.0, gamma=0.2, learning_rate=0.2, max_depth=5, min_child_weight=3, n_estimators=300, subsample=0.6; total time= 4.6s
[CV] END colsample_bytree=1.0, gamma=0.1, learning_rate=0.05, max_depth=10, min_child_weight=3, n_estimators=500, subsample=0.8; total time= 28.5s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.01, max_depth=3, min_child_weight=1, n_estimators=100, subsample=0.8; total time= 0.6s
[CV] END colsample_bytree=1.0, gamma=0.1, learning_rate=0.01, max_depth=3, min_child_weight=7, n_estimators=100, subsample=0.8; total time= 0.6s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.01, max_depth=3, min_child_weight=1, n_estimators=100, subsample=0.8; total time= 0.9s
[CV] END colsample_bytree=1.0, gamma=0.1, learning_rate=0.01, max_depth=3, min_child_weight=7, n_estimators=100, subsample=0.8; total time= 0.8s
[CV] END colsample_bytree=1.0, gamma=0.1, learning_rate=0.01, max_depth=3, min_child_weight=7, n_estimators=100, subsample=0.8; total time= 0.9s
[CV] END colsample_bytree=1.0, gamma=0.1, learning_rate=0.01, max_depth=3, min_child_weight=7, n_estimators=100, subsample=0.8; total time= 0.6s
[CV] END colsample_bytree=1.0, gamma=0.1, learning_rate=0.01, max_depth=3, min_child_weight=7, n_estimators=100, subsample=0.8; total time= 1.0s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.2, max_depth=7, min_child_weight=5, n_estimators=300, subsample=0.8; total time= 5.1s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.01, max_depth=7, min_child_weight=5, n_estimators=500, subsample=0.6; total time= 6.9s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.01, max_depth=7, min_child_weight=5, n_estimators=500, subsample=0.6; total time= 7.3s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.2, max_depth=7, min_child_weight=5, n_estimators=300, subsample=0.8; total time= 6.6s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.01, max_depth=7, min_child_weight=5, n_estimators=500, subsample=0.6; total time= 6.9s
[CV] END colsample_bytree=0.6, gamma=0.2, learning_rate=0.01, max_depth=10, min_child_weight=1, n_estimators=200, subsample=1.0; total time= 12.1s
[CV] END colsample_bytree=0.6, gamma=0.2, learning_rate=0.01, max_depth=10, min_child_weight=1, n_estimators=200, subsample=1.0; total time= 12.2s[CV] END colsample_bytree=0.6, gamma=0.2, learning_rate=0.01, max_depth=10, min_child_weight=1, n_estimators=200, subsample=1.0; total time= 11.9s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.01, max_depth=7, min_child_weight=5, n_estimators=500, subsample=0.6; total time= 9.6s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.2, max_depth=7, min_child_weight=5, n_estimators=300, subsample=0.8; total time= 4.3s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.01, max_depth=7, min_child_weight=5, n_estimators=500, subsample=0.6; total time= 9.9s
[CV] END colsample_bytree=0.6, gamma=0.2, learning_rate=0.01, max_depth=10, min_child_weight=1, n_estimators=200, subsample=1.0; total time= 12.0s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.05, max_depth=5, min_child_weight=7, n_estimators=100, subsample=0.6; total time= 0.9s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.05, max_depth=5, min_child_weight=7, n_estimators=100, subsample=0.6; total time= 1.0s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.05, max_depth=5, min_child_weight=7, n_estimators=100, subsample=0.6; total time= 0.8s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.05, max_depth=5, min_child_weight=7, n_estimators=100, subsample=0.6; total time= 1.0s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.1, max_depth=5, min_child_weight=1, n_estimators=500, subsample=1.0; total time= 3.9s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.2, max_depth=7, min_child_weight=5, n_estimators=300, subsample=0.8; total time= 4.1s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.2, max_depth=7, min_child_weight=5, n_estimators=300, subsample=0.8; total time= 4.3s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.05, max_depth=5, min_child_weight=7, n_estimators=100, subsample=0.6; total time= 0.9s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.1, max_depth=5, min_child_weight=1, n_estimators=500, subsample=1.0; total time= 5.0s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.1, max_depth=3, min_child_weight=5, n_estimators=300, subsample=1.0; total time= 1.2s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.1, max_depth=3, min_child_weight=5, n_estimators=300, subsample=1.0; total time= 1.4s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.1, max_depth=5, min_child_weight=1, n_estimators=500, subsample=1.0; total time= 3.6s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.1, max_depth=3, min_child_weight=5, n_estimators=300, subsample=1.0; total time= 1.3s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.1, max_depth=3, min_child_weight=5, n_estimators=300, subsample=1.0; total time= 1.3s
[CV] END colsample_bytree=0.6, gamma=0.1, learning_rate=0.1, max_depth=3, min_child_weight=5, n_estimators=300, subsample=1.0; total time= 1.4s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.1, max_depth=5, min_child_weight=1, n_estimators=500, subsample=1.0; total time= 3.7s
[CV] END colsample_bytree=0.8, gamma=0.2, learning_rate=0.1, max_depth=5, min_child_weight=1, n_estimators=500, subsample=1.0; total time= 3.9s
[CV] END colsample_bytree=0.6, gamma=0.2, learning_rate=0.01, max_depth=10, min_child_weight=1, n_estimators=200, subsample=1.0; total time= 16.7s
[CV] END colsample_bytree=0.8, gamma=0, learning_rate=0.05, max_depth=7, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 1.6s
[CV] END colsample_bytree=0.8, gamma=0, learning_rate=0.05, max_depth=7, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 1.6s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.05, max_depth=5, min_child_weight=3, n_estimators=100, subsample=0.6; total time= 1.2s
[CV] END colsample_bytree=0.8, gamma=0, learning_rate=0.05, max_depth=7, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 1.8s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.05, max_depth=5, min_child_weight=3, n_estimators=100, subsample=0.6; total time= 1.0s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.05, max_depth=5, min_child_weight=3, n_estimators=100, subsample=0.6; total time= 1.1s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.05, max_depth=5, min_child_weight=3, n_estimators=100, subsample=0.6; total time= 1.9s
[CV] END colsample_bytree=0.8, gamma=0, learning_rate=0.05, max_depth=7, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 2.9s
[CV] END colsample_bytree=1.0, gamma=0, learning_rate=0.05, max_depth=5, min_child_weight=3, n_estimators=100, subsample=0.6; total time= 1.2s
[CV] END colsample_bytree=1.0, gamma=0.5, learning_rate=0.05, max_depth=3, min_child_weight=5, n_estimators=100, subsample=1.0; total time= 0.8s
[CV] END colsample_bytree=0.8, gamma=0.1, learning_rate=0.2, max_depth=7, min_child_weight=7, n_estimators=300, subsample=0.8; total time= 3.7s
[CV] END colsample_bytree=0.8, gamma=0, learning_rate=0.05, max_depth=7, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 2.9s
[CV] END colsample_bytree=0.8, gamma=0.1, learning_rate=0.2, max_depth=7, min_child_weight=7, n_estimators=300, subsample=0.8; total time= 4.3s
[CV] END colsample_bytree=1.0, gamma=0.5, learning_rate=0.05, max_depth=3, min_child_weight=5, n_estimators=100, subsample=1.0; total time= 0.5s
[CV] END colsample_bytree=1.0, gamma=0.5, learning_rate=0.05, max_depth=3, min_child_weight=5, n_estimators=100, subsample=1.0; total time= 0.6s
[CV] END colsample_bytree=0.8, gamma=0.1, learning_rate=0.2, max_depth=7, min_child_weight=7, n_estimators=300, subsample=0.8; total time= 3.6s
[CV] END colsample_bytree=1.0, gamma=0.5, learning_rate=0.05, max_depth=3, min_child_weight=5, n_estimators=100, subsample=1.0; total time= 0.9s
[CV] END colsample_bytree=1.0, gamma=0.5, learning_rate=0.05, max_depth=3, min_child_weight=5, n_estimators=100, subsample=1.0; total time= 0.8s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.05, max_depth=5, min_child_weight=3, n_estimators=100, subsample=1.0; total time= 0.8s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.05, max_depth=5, min_child_weight=3, n_estimators=100, subsample=1.0; total time= 1.0s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.05, max_depth=5, min_child_weight=3, n_estimators=100, subsample=1.0; total time= 1.0s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.05, max_depth=5, min_child_weight=3, n_estimators=100, subsample=1.0; total time= 1.0s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.05, max_depth=5, min_child_weight=3, n_estimators=100, subsample=1.0; total time= 1.0s
[CV] END colsample_bytree=0.8, gamma=0.1, learning_rate=0.2, max_depth=7, min_child_weight=7, n_estimators=300, subsample=0.8; total time= 4.4s
[CV] END colsample_bytree=0.8, gamma=0.1, learning_rate=0.2, max_depth=7, min_child_weight=7, n_estimators=300, subsample=0.8; total time= 5.5s
[CV] END colsample_bytree=0.6, gamma=0.2, learning_rate=0.1, max_depth=7, min_child_weight=5, n_estimators=300, subsample=0.8; total time= 2.4s
[CV] END colsample_bytree=0.6, gamma=0.2, learning_rate=0.1, max_depth=7, min_child_weight=5, n_estimators=300, subsample=0.8; total time= 2.5s
[CV] END colsample_bytree=0.6, gamma=0.2, learning_rate=0.1, max_depth=7, min_child_weight=5, n_estimators=300, subsample=0.8; total time= 2.6s
[CV] END colsample_bytree=0.6, gamma=0.2, learning_rate=0.1, max_depth=7, min_child_weight=5, n_estimators=300, subsample=0.8; total time= 2.6s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.1, max_depth=5, min_child_weight=1, n_estimators=500, subsample=1.0; total time= 2.6s
[CV] END colsample_bytree=0.6, gamma=0.2, learning_rate=0.1, max_depth=7, min_child_weight=5, n_estimators=300, subsample=0.8; total time= 3.0s
[CV] END colsample_bytree=1.0, gamma=0.2, learning_rate=0.01, max_depth=10, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 4.0s
[CV] END colsample_bytree=1.0, gamma=0.2, learning_rate=0.01, max_depth=10, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 4.3s
[CV] END colsample_bytree=1.0, gamma=0.2, learning_rate=0.01, max_depth=10, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 4.7s
[CV] END colsample_bytree=1.0, gamma=0.2, learning_rate=0.01, max_depth=10, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 4.4s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.1, max_depth=5, min_child_weight=1, n_estimators=500, subsample=1.0; total time= 3.0s
[CV] END colsample_bytree=1.0, gamma=0.2, learning_rate=0.01, max_depth=10, min_child_weight=5, n_estimators=100, subsample=0.8; total time= 4.7s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.1, max_depth=5, min_child_weight=1, n_estimators=500, subsample=1.0; total time= 3.2s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.1, max_depth=5, min_child_weight=1, n_estimators=500, subsample=1.0; total time= 3.4s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.1, max_depth=5, min_child_weight=1, n_estimators=500, subsample=1.0; total time= 3.6s
[CV] END colsample_bytree=1.0, gamma=0.5, learning_rate=0.2, max_depth=7, min_child_weight=7, n_estimators=500, subsample=1.0; total time= 4.7s
[CV] END colsample_bytree=1.0, gamma=0.5, learning_rate=0.2, max_depth=7, min_child_weight=7, n_estimators=500, subsample=1.0; total time= 4.5s
[CV] END colsample_bytree=1.0, gamma=0.5, learning_rate=0.2, max_depth=7, min_child_weight=7, n_estimators=500, subsample=1.0; total time= 5.0s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.1, max_depth=3, min_child_weight=7, n_estimators=500, subsample=0.8; total time= 2.1s
[CV] END colsample_bytree=1.0, gamma=0.5, learning_rate=0.2, max_depth=7, min_child_weight=7, n_estimators=500, subsample=1.0; total time= 4.5s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.1, max_depth=3, min_child_weight=7, n_estimators=500, subsample=0.8; total time= 2.1s
[CV] END colsample_bytree=1.0, gamma=0.5, learning_rate=0.2, max_depth=7, min_child_weight=7, n_estimators=500, subsample=1.0; total time= 5.2s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.1, max_depth=3, min_child_weight=7, n_estimators=500, subsample=0.8; total time= 2.1s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.1, max_depth=3, min_child_weight=7, n_estimators=500, subsample=0.8; total time= 2.0s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.1, max_depth=3, min_child_weight=7, n_estimators=500, subsample=0.8; total time= 2.0s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.2, max_depth=7, min_child_weight=5, n_estimators=200, subsample=1.0; total time= 2.1s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.2, max_depth=7, min_child_weight=5, n_estimators=200, subsample=1.0; total time= 2.2s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.2, max_depth=7, min_child_weight=5, n_estimators=200, subsample=1.0; total time= 2.1s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.2, max_depth=7, min_child_weight=5, n_estimators=200, subsample=1.0; total time= 2.2s
[CV] END colsample_bytree=0.6, gamma=0.5, learning_rate=0.2, max_depth=7, min_child_weight=5, n_estimators=200, subsample=1.0; total time= 1.9s
[CV] END colsample_bytree=0.6, gamma=0, learning_rate=0.01, max_depth=10, min_child_weight=7, n_estimators=500, subsample=0.6; total time= 9.5s
[CV] END colsample_bytree=0.6, gamma=0, learning_rate=0.01, max_depth=10, min_child_weight=7, n_estimators=500, subsample=0.6; total time= 10.0s
[CV] END colsample_bytree=0.6, gamma=0, learning_rate=0.01, max_depth=10, min_child_weight=7, n_estimators=500, subsample=0.6; total time= 9.8s
[CV] END colsample_bytree=0.6, gamma=0, learning_rate=0.01, max_depth=10, min_child_weight=7, n_estimators=500, subsample=0.6; total time= 10.1s
[CV] END colsample_bytree=0.6, gamma=0, learning_rate=0.01, max_depth=10, min_child_weight=7, n_estimators=500, subsample=0.6; total time= 9.3s