Big Data and Cloud Platforms (Module 2)
Data pipelines on cloud (Computing)

Computing
Supporting data pipelines: IaaS
- Outsource virtual machines to the cloud (AWS EC2)
- (You) Manage technological and business challenges

Single instance: AWS EC2
Amazon Elastic Compute Cloud (EC2)
- A web service that provides resizable computing capacity
- Complete control of computing resources
- Processor, storage, networking, OS, and purchase model
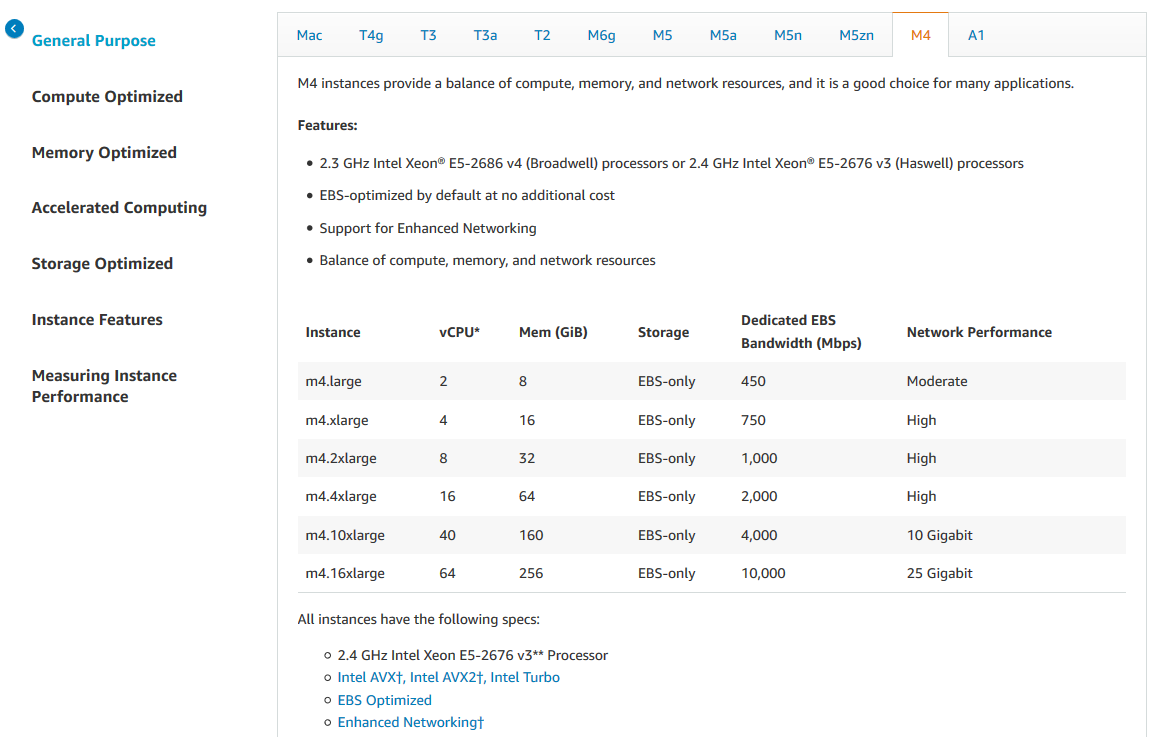
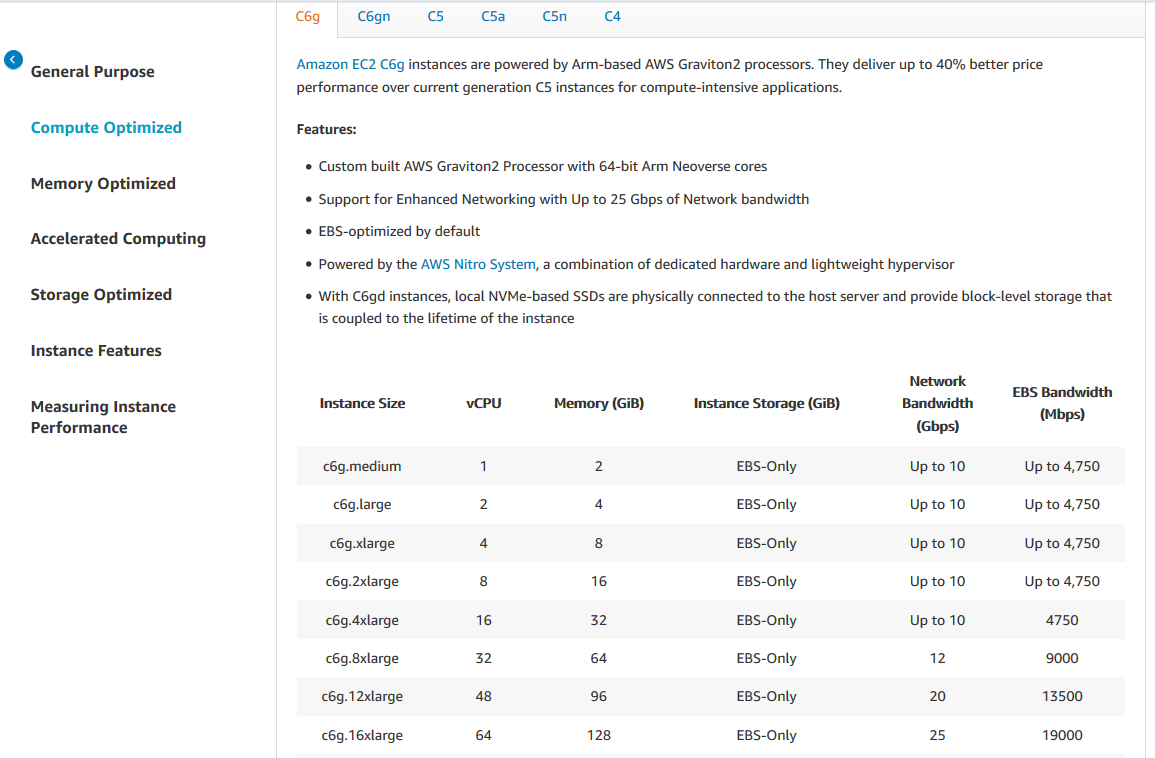
The instance type determines the hardware
- Different compute and memory capabilities
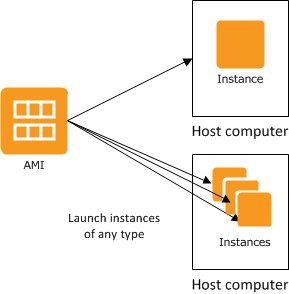
Amazon Machine Image is a software template
- The EC2 instance is used for creating the virtual server instance
- The AMI is the EC2 virtual machine image
Interact with EC2 instance as with any computer
- You have complete control of your instances
Single instance: AWS EC2
Supporting data pipelines: PaaS
- Outsource the data ecosystem to the cloud (e.g., AWS EMR)
- (You) Manage business challenges

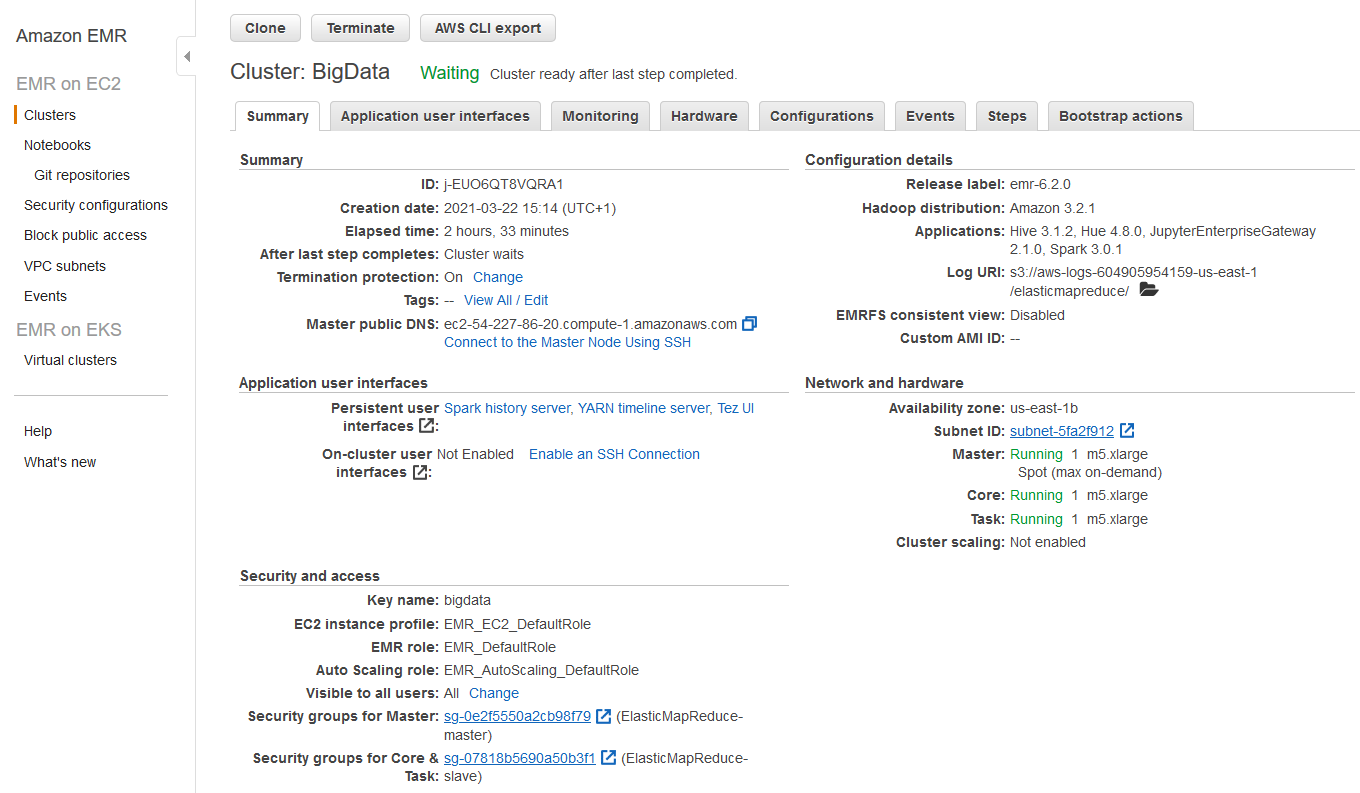
AWS EMR


AWS EMR
EMR cluster
Master group
- Control the cluster
- Coordinate the work distribution
- Manage the cluster state
Core groups
- Run Data Node (HDFS) daemons
(Optional) Task instances
- Provide computational power

Creating the cluster
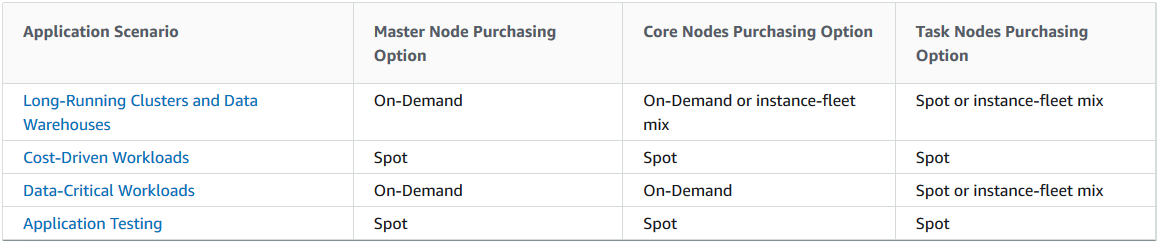
Creating the cluster
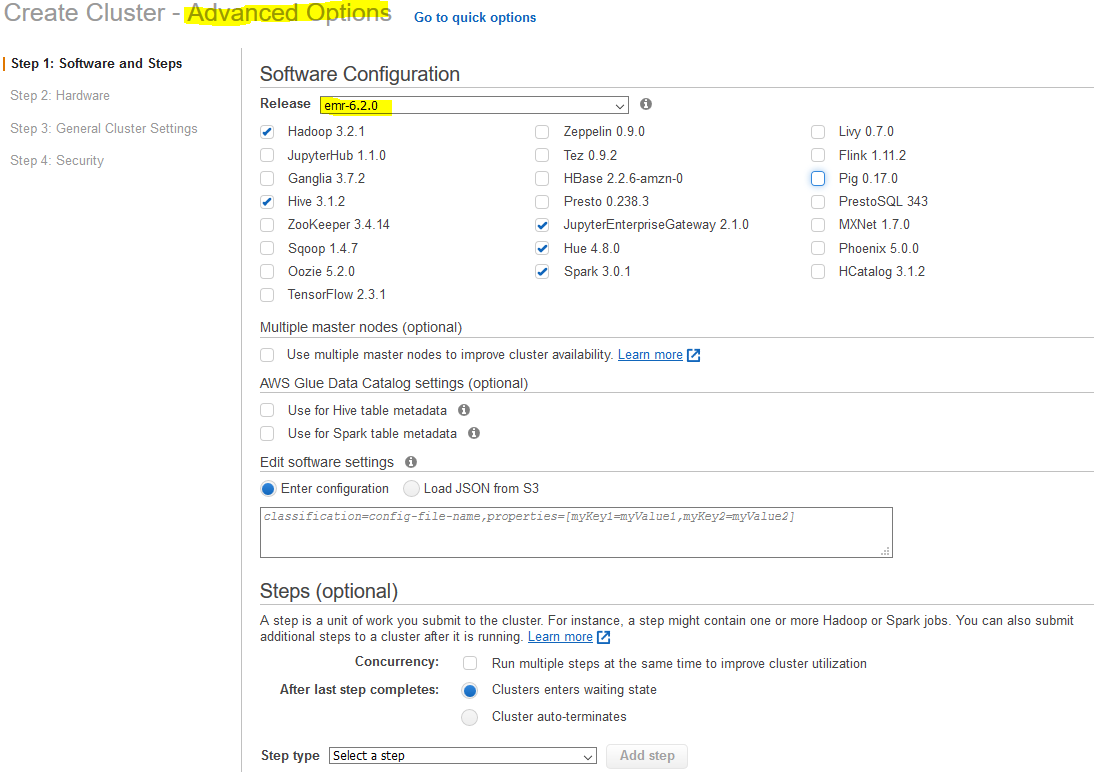
Software and steps
Creating the cluster
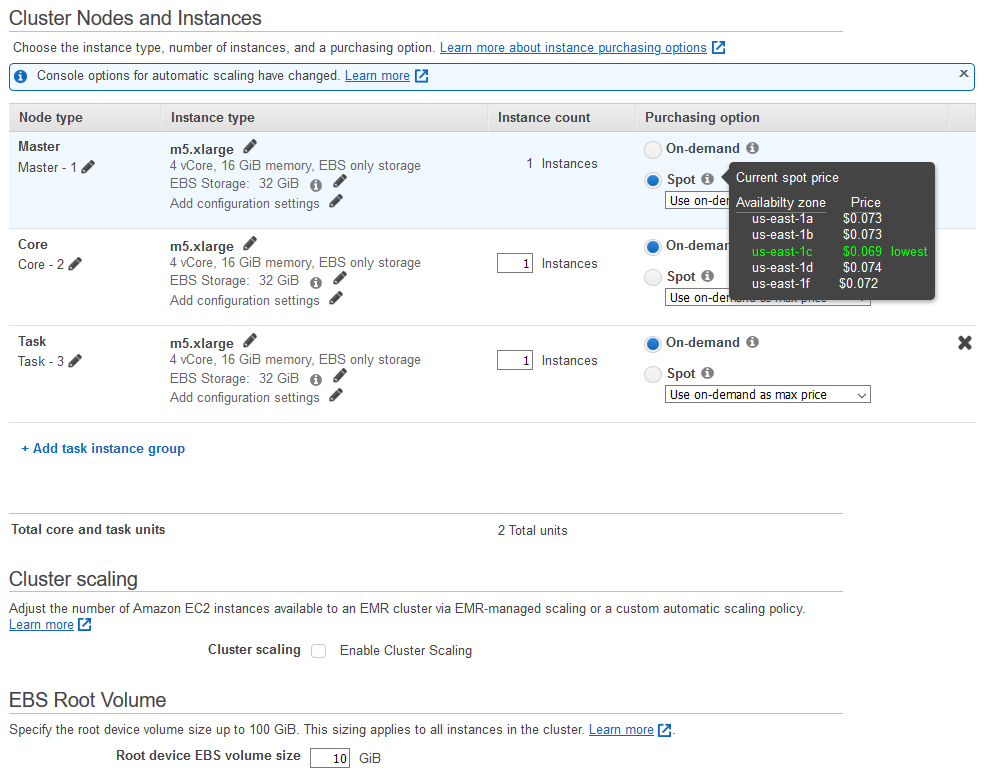
Hardware
Creating the cluster
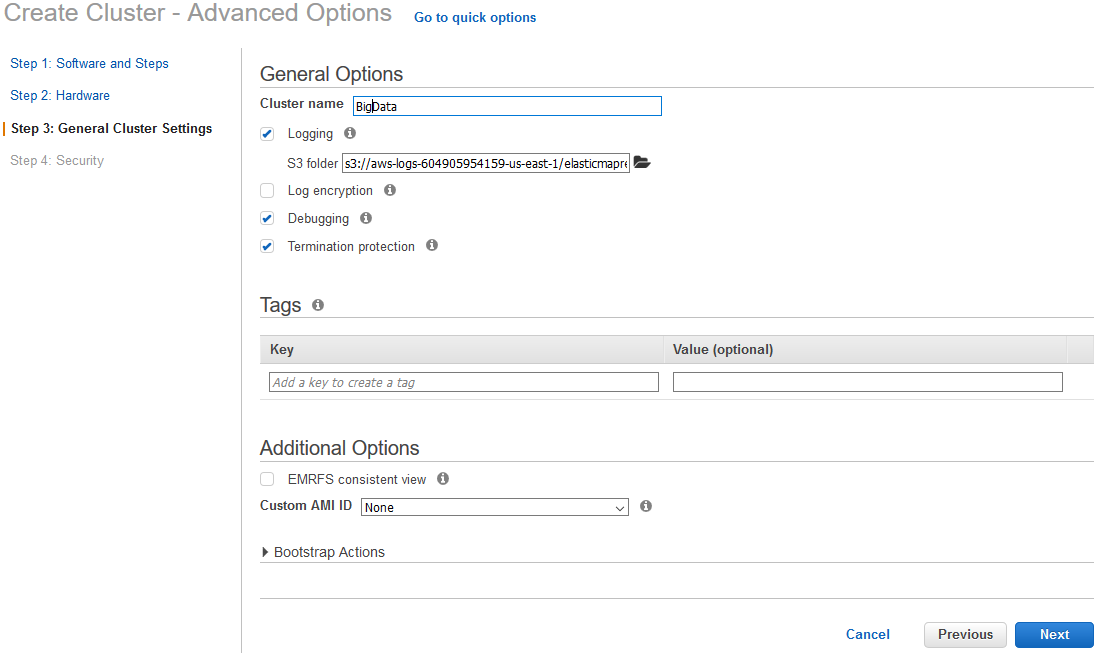
General cluster settings
Creating the cluster
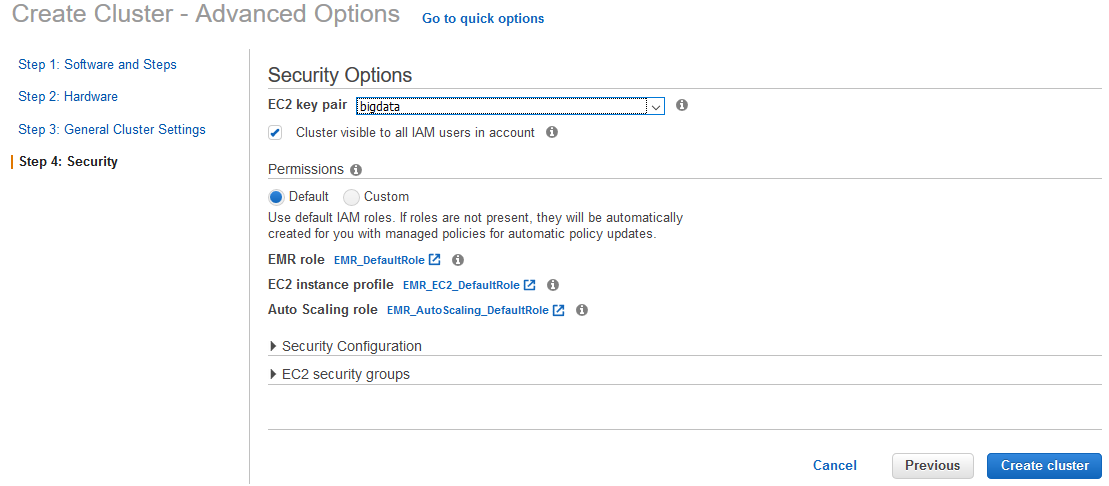
Security
Cluster lifecycle
Creating a cluster (it takes ~10 minutes)
- A cluster cannot be stopped
- It can only be terminated
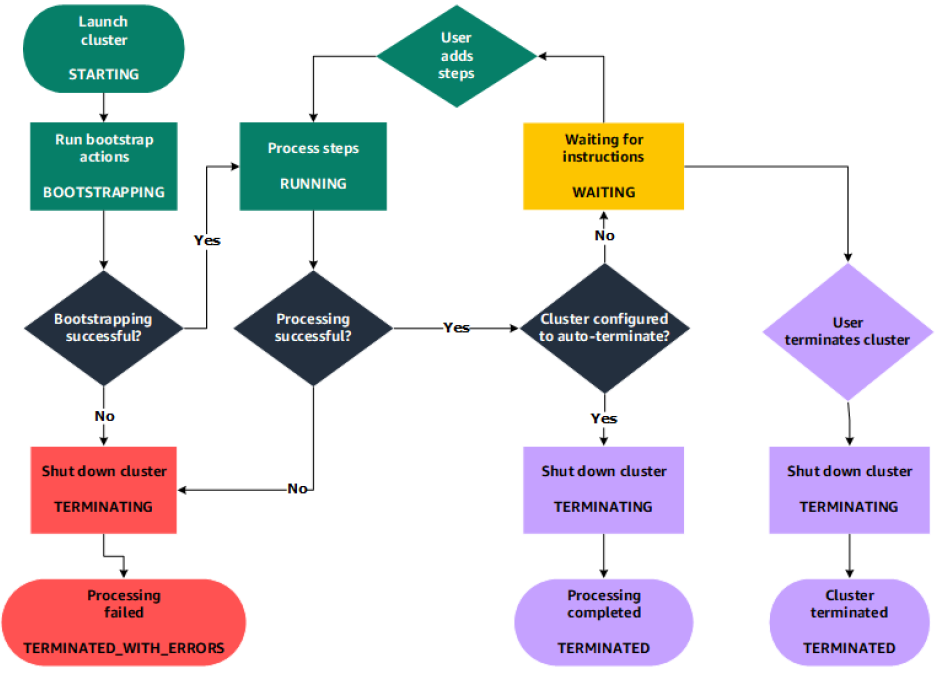
Running the cluster
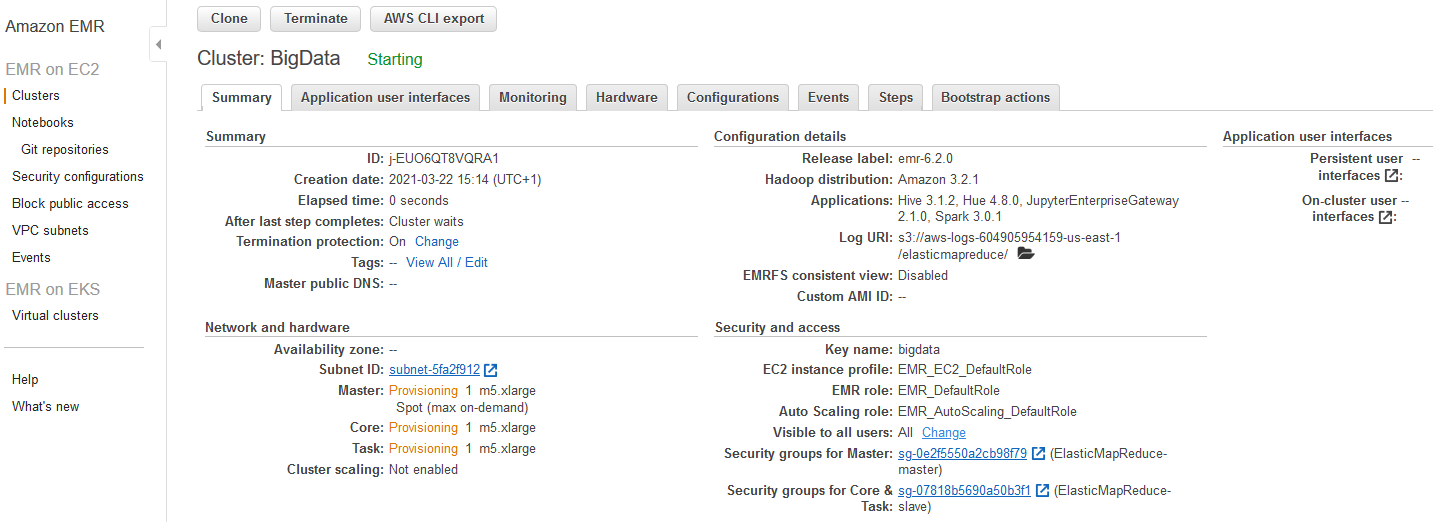
Running the cluster