Machine Learning and Data Mining (Module 2)
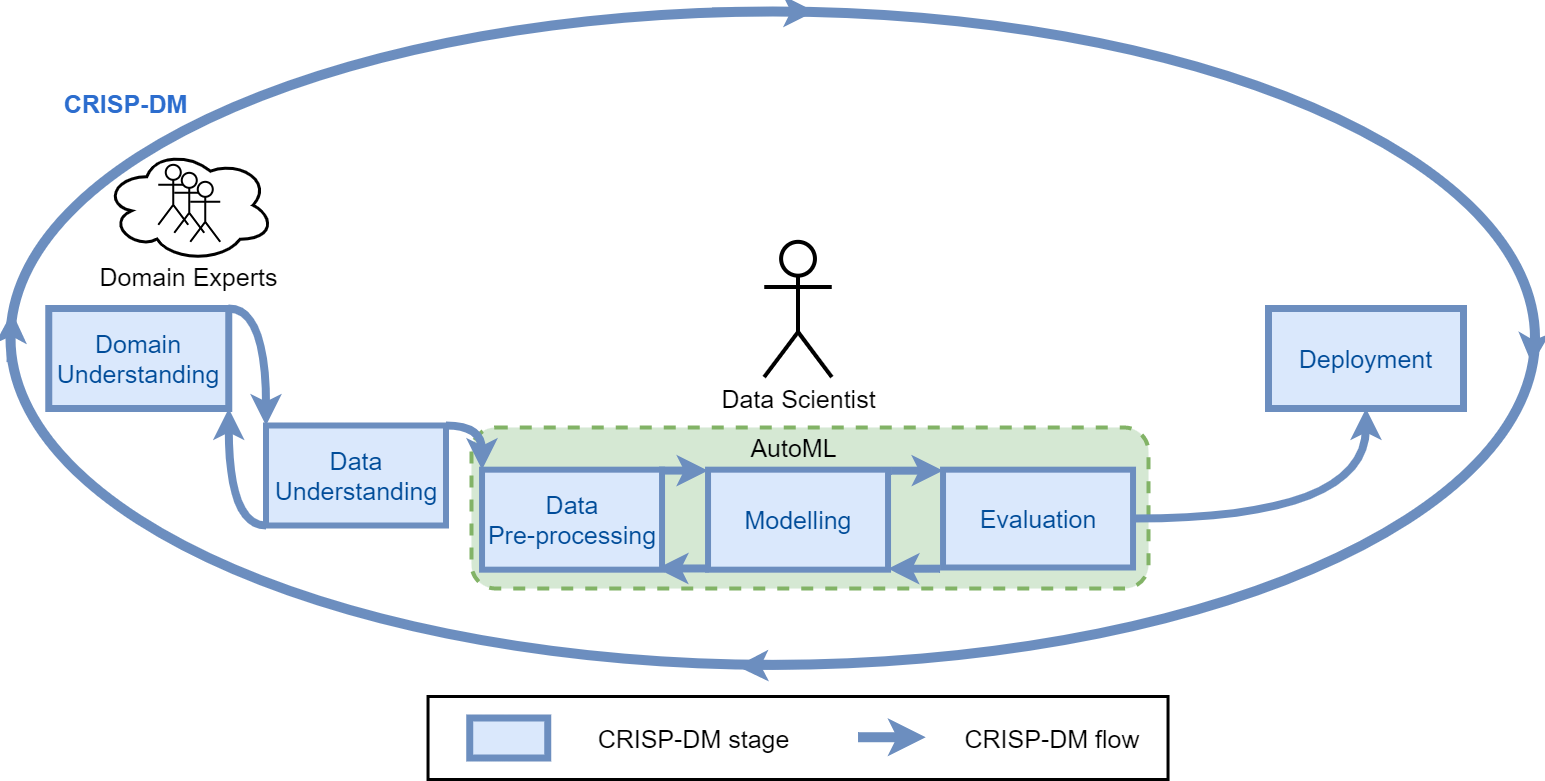
CRISP-DM
The CRoss Industry Standard Process for Data Mining (CRISP-DM) is a process model that serves as the base for a data science process.
It has six sequential phases:
- Business understanding – What does the business need?
- Data understanding – What data do we have / need? Is it clean?
- Data preparation – How do we organize the data for modeling?
- Modeling – What modeling techniques should we apply?
- Evaluation – Which model best meets the business objectives?
- Deployment – How do stakeholders access the results?

Pipelines for ML tasks
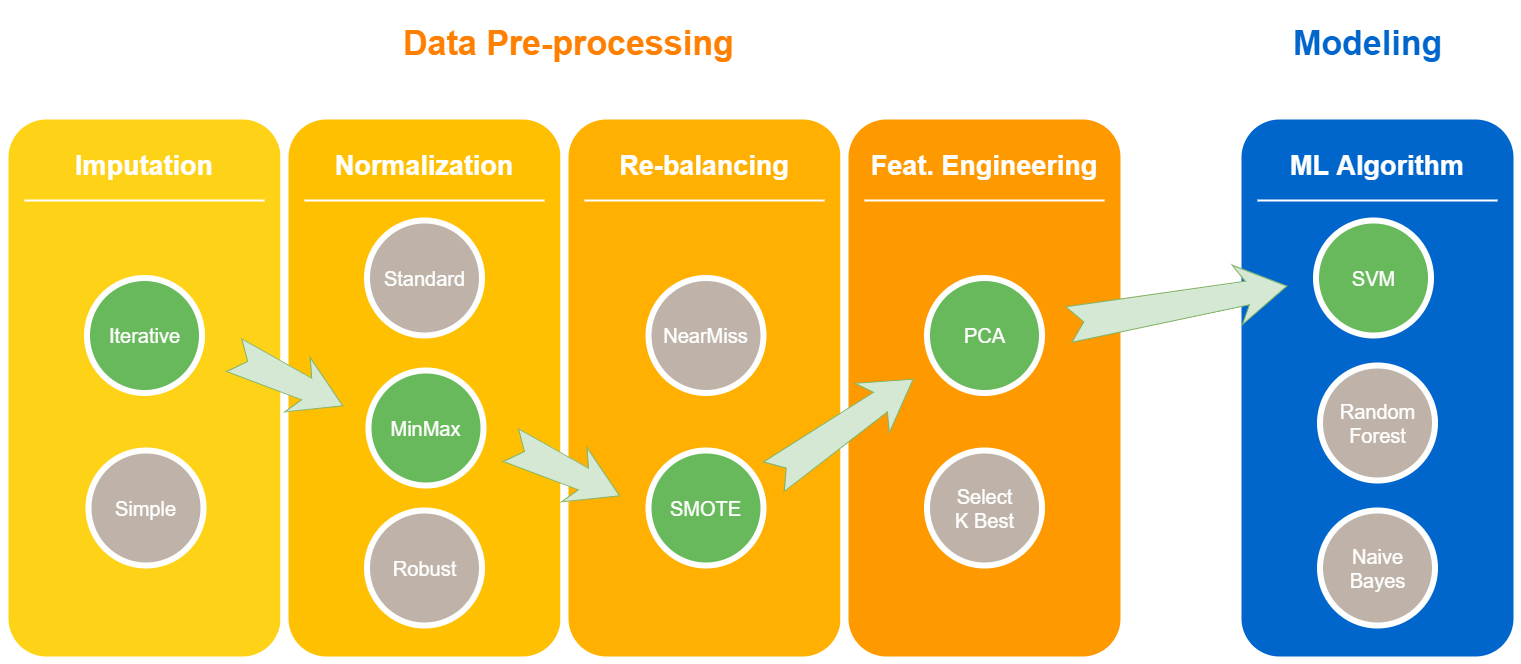
ML pipeline
Pipelines for ML tasks
Tuning pipelines is hard
- At each step, a technique must be selected
- For each technique, a set of hyper-parameters must be set
- Each hyper-parameter has its own search space
Pipelines for ML tasks
HAMLET: (Francia et al. 2023)
AutoML
AutoML aims at automating the ML pipeline instantiation:
- it is difficult to consider all the constraints together;
- it is not transparent;
- it doesn’t allow a proper knowledge augmentation.
Examples of AutoML tools:
- Auto-WEKA (Thornton et al. 2013)
- Auto-sklearn (Feurer et al. 2022)
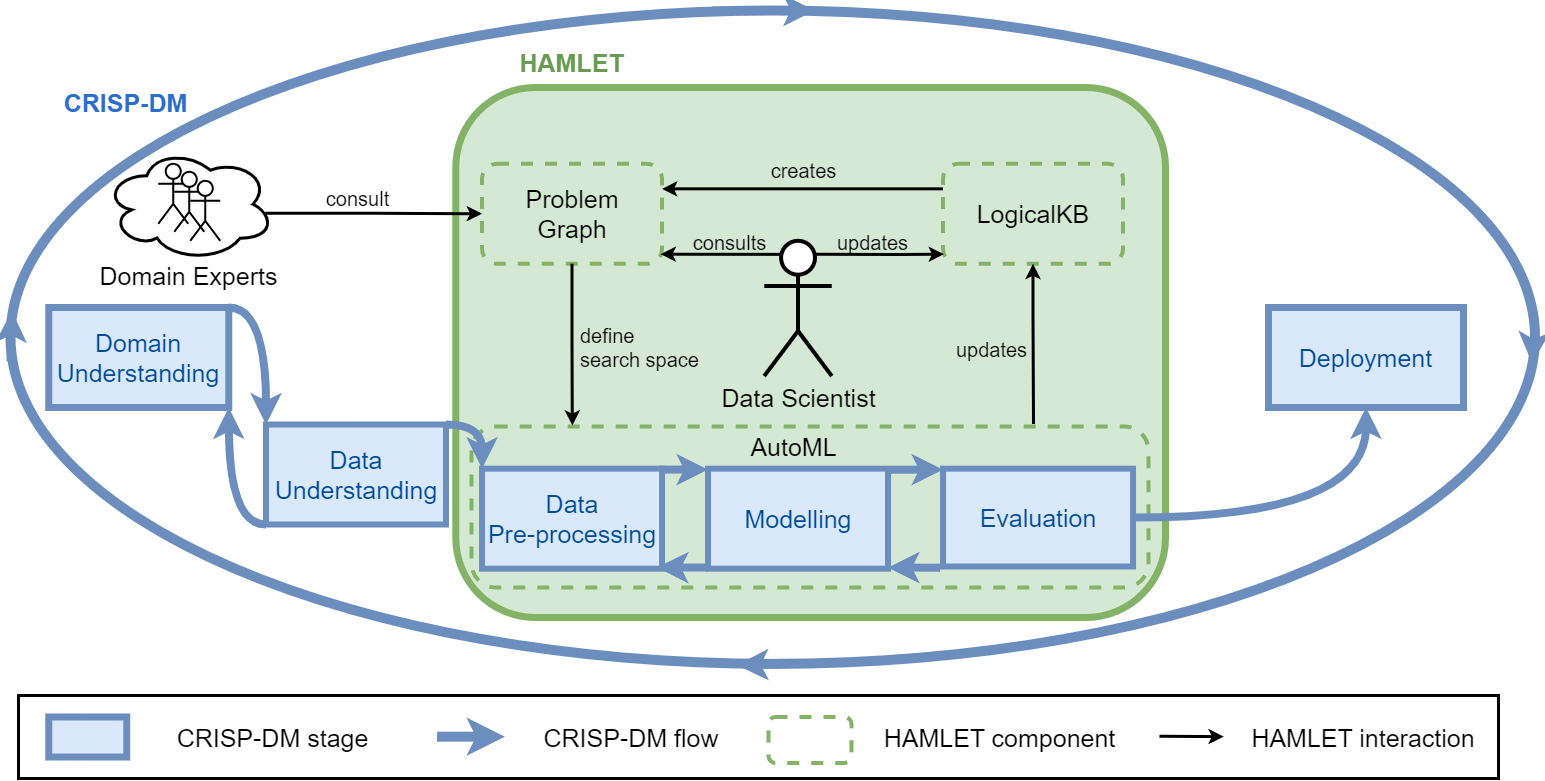
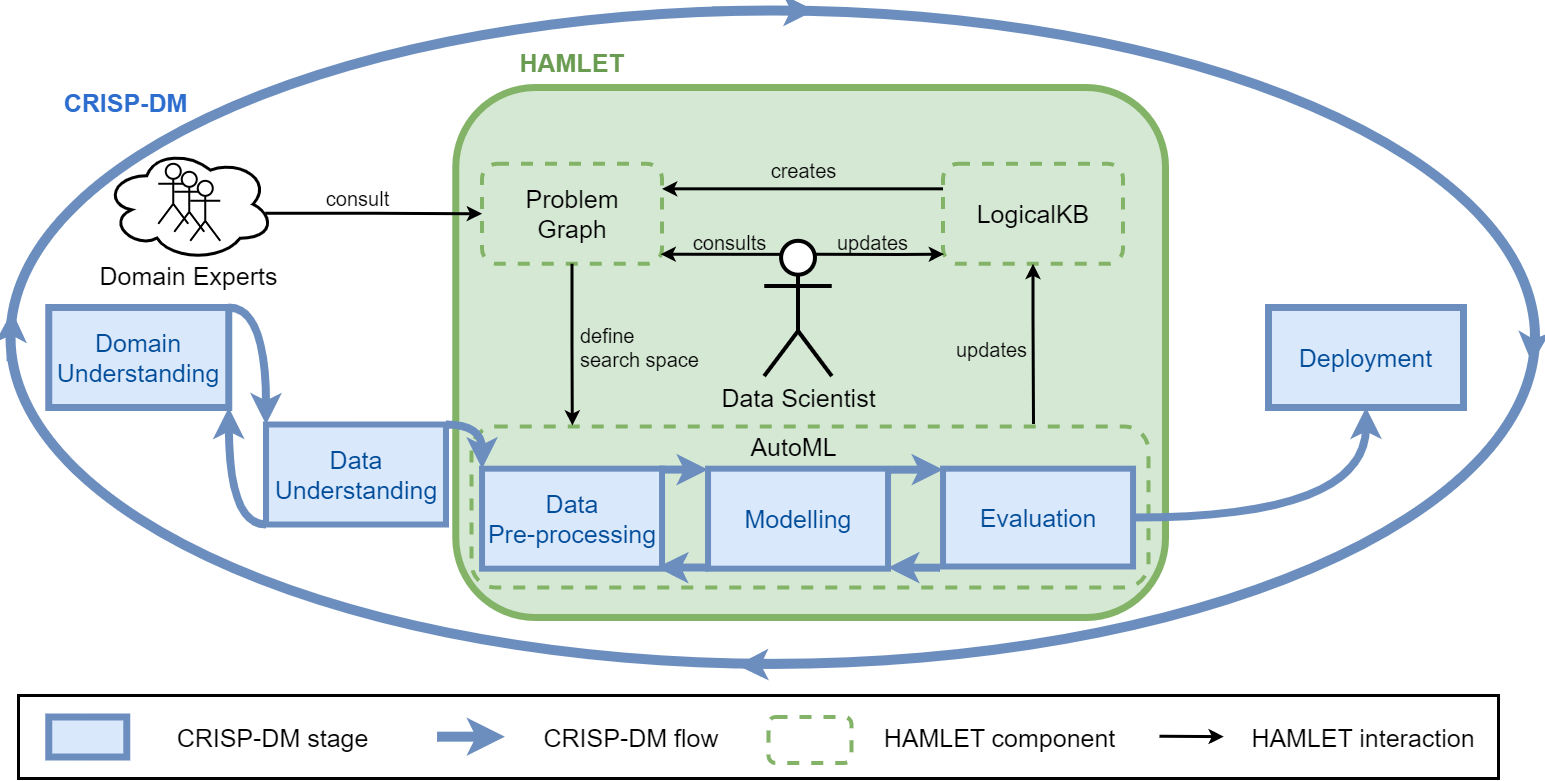
HAMLET
HAMLET: Human-centric AutoML via Logic and Argumentation
- Logic to give a structure to the knowledge;
- Argumentation to deal with inconsistencies, and revise the results.
HAMLET
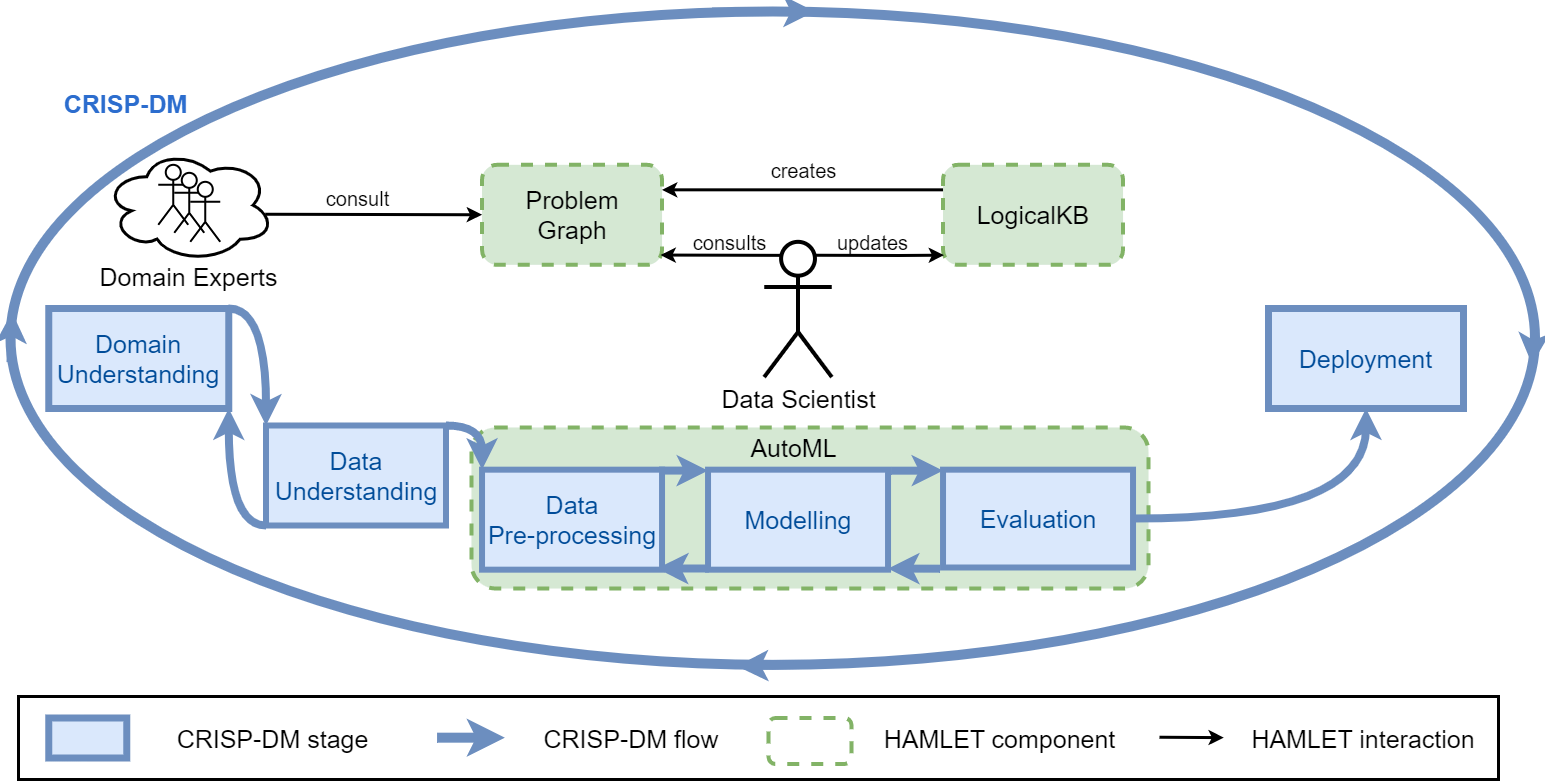
The LogicalKB enables:
- the Data Scientist to structure the ML constraints;
- the AutoML tool to encode the explored results

HAMLET
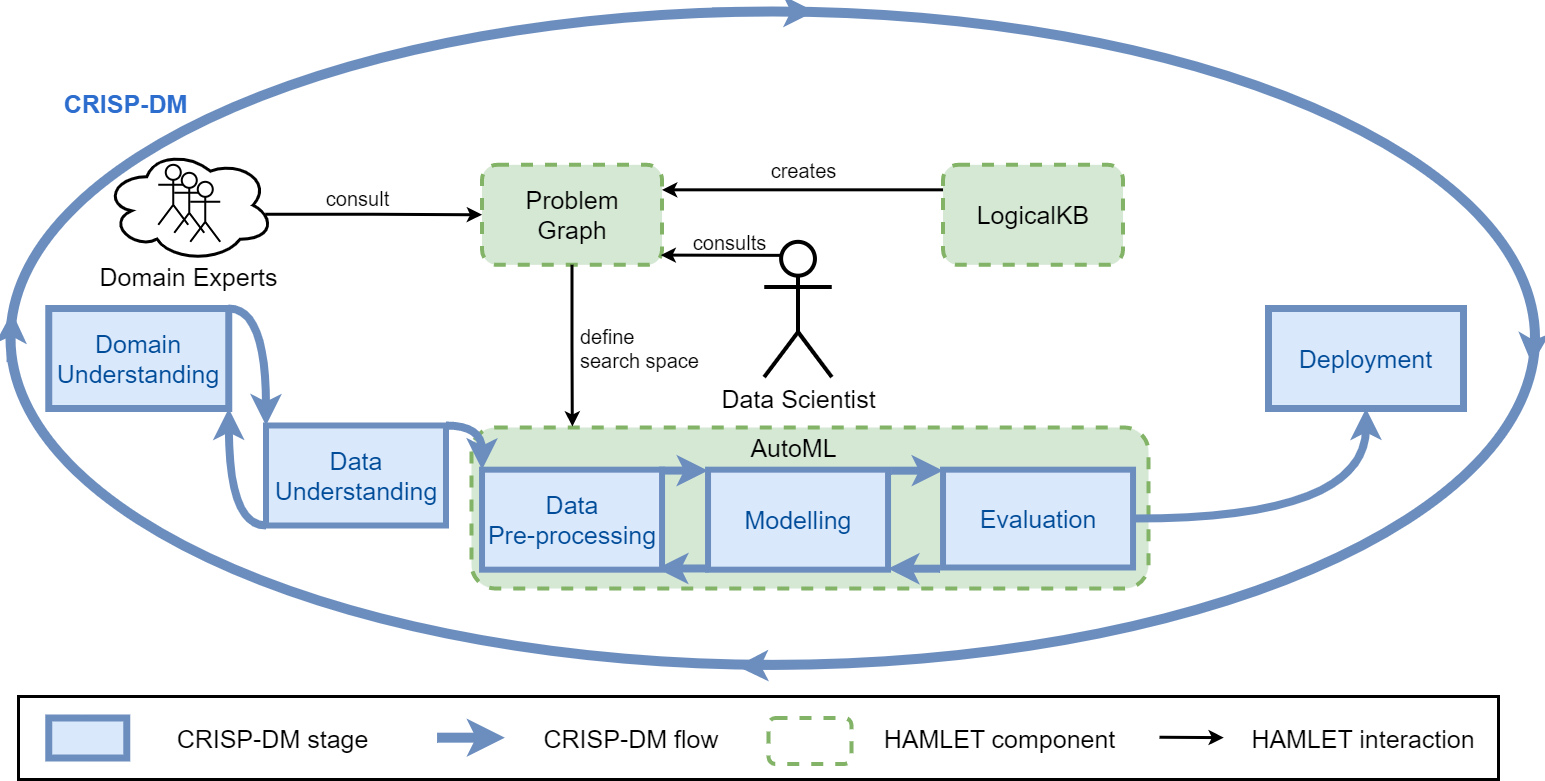
The Problem Graph allows to:
- consider all the ML constraints together;
- set up the AutoML search space;
- discuss and argument about the results.
HAMLET
The Data Scientist iterates on:
- editing the LogicalKB;
- consulting the Problem Graph;
- running the AutoML tool;
- discussing the AutoML insights.
KB and Problem Graph
KB and Problem Graph

KB and Problem Graph
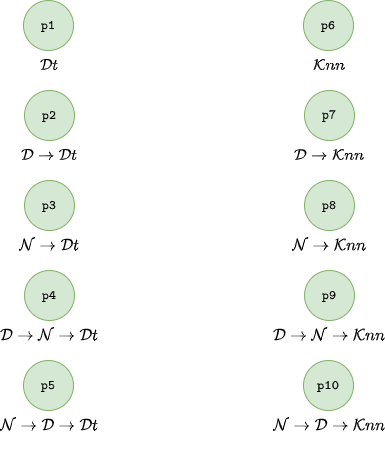
// Declare steps pipeline
s1 : ⇒ step(D).
s2 : ⇒ step(N).
s3 : ⇒ step(Cl).
// Declare classification algorithms
a1 : ⇒ algorithm(Cl, Dt).
a2 : ⇒ algorithm(Cl, Knn).
// Forbid Normalization when using DT
c1 : ⇒ forbidden(⟨N⟩, Dt).
// Mandatory Normalization in Classification Pipelines
c2 : ⇒ mandatory(⟨N⟩, Cl).
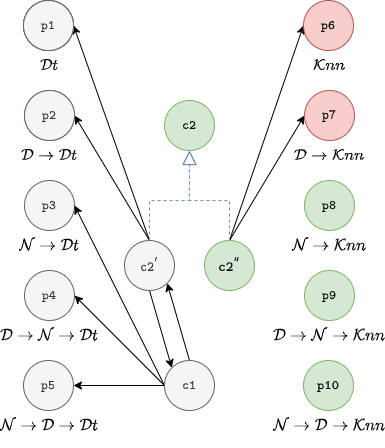
KB and Problem Graph
// Declare steps pipeline
s1 : ⇒ step(D).
s2 : ⇒ step(N).
s3 : ⇒ step(Cl).
// Declare classification algorithms
a1 : ⇒ algorithm(Cl, Dt).
a2 : ⇒ algorithm(Cl, Knn).
// Forbid Normalization when using DT
c1 : ⇒ forbidden(⟨N⟩, Dt).
// Mandatory Normalization in Classification Pipelines
c2 : ⇒ mandatory(⟨N⟩, Cl).Conflict between c1 and c2!
KB and Problem Graph
// Declare steps pipeline
s1 : ⇒ step(D).
s2 : ⇒ step(N).
s3 : ⇒ step(Cl).
// Declare classification algorithms
a1 : ⇒ algorithm(Cl, Dt).
a2 : ⇒ algorithm(Cl, Knn).
// Forbid Normalization when using DT
c1 : ⇒ forbidden(⟨N⟩, Dt).
// Mandatory Normalization in Classification Pipelines
c2 : ⇒ mandatory(⟨N⟩, Cl).
// Resolve conflict between c1 and c2
sup(c1, c2).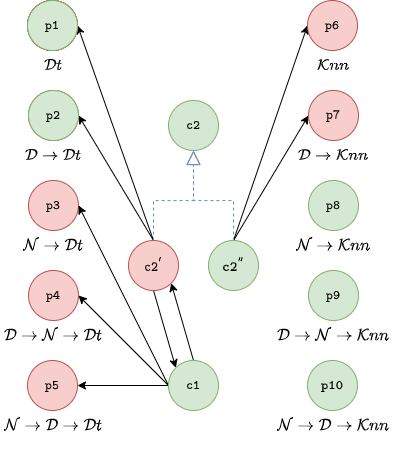
Evaluation
Settings:
- Baseline: 1 optimization it. of 60 mins;
- PKB (Preliminary Knowledge Base): 1 optimization it. of 60 mins with non-empty LogicalKB;
- IKA (Iterative Knowledge Augmentation): 4 optimization it. of 15 mins with empty LogicalKB;
- PKB + IKA: 4 optimization it. of 15 mins with non-empty LogicalKB.
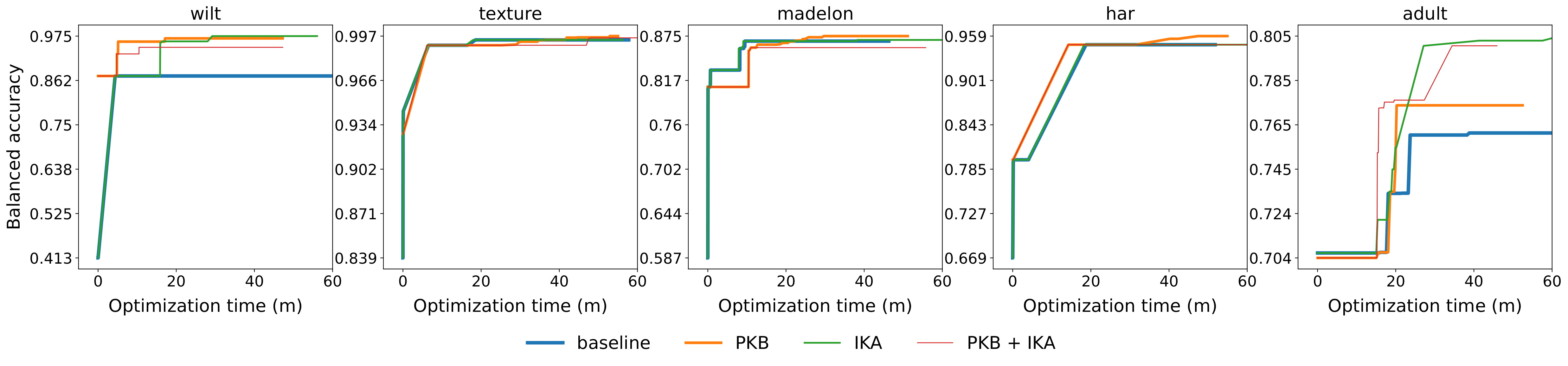
Accuracy vs budget
Evaluation
Settings:
- Baseline: 1 optimization iteration of 60 mins;
- PKB (Preliminary Knowledge Base): 1 optimization iteration of 60 mins with non-empty LogicalKB;
- IKA (Iterative Knowledge Augmentation): 4 optimization iterations of 15 mins with empty LogicalKB;
- PKB + IKA: 4 optimization iterations of 15 mins with non-empty LogicalKB.
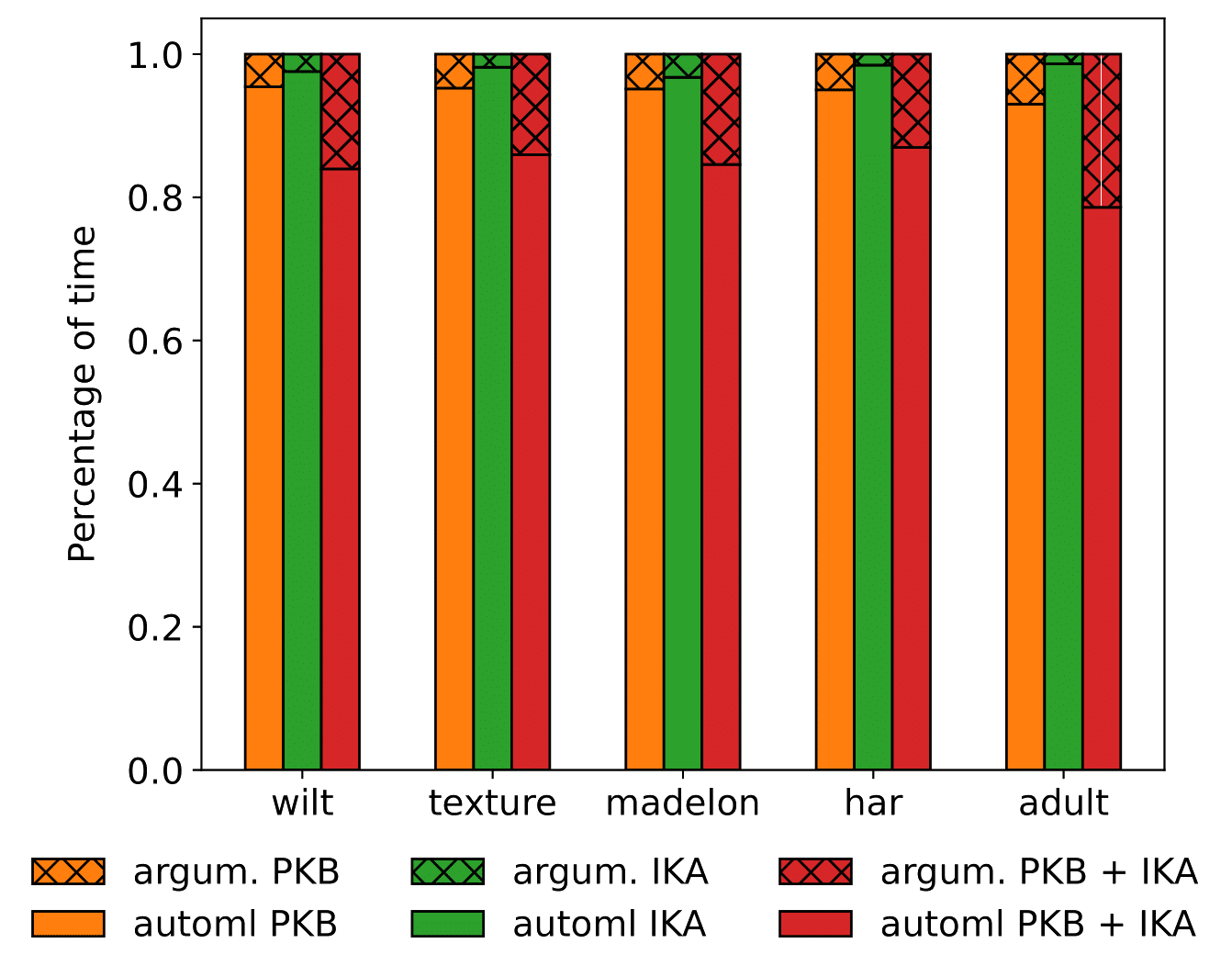
Computational overhead
Comparison with AutoML tools
Evaluation

Accuracy vs AutoML tools
HAMLET
Key features:
- knowledge injection;
- representation via an human- and
- machine-readable medium;
- insight discovery;
- dealing with possible arising inconsistencies.
Future directions:
- make constraints fuzzy;
- improve recommendation algorithm;
- enhance HAMLET with meta-learning;
- manage cross-cutting constraints (e.g., ethic, legal).