Data Platforms and Artificial Intelligence
Challenges and Applications
How should metadata be organized?
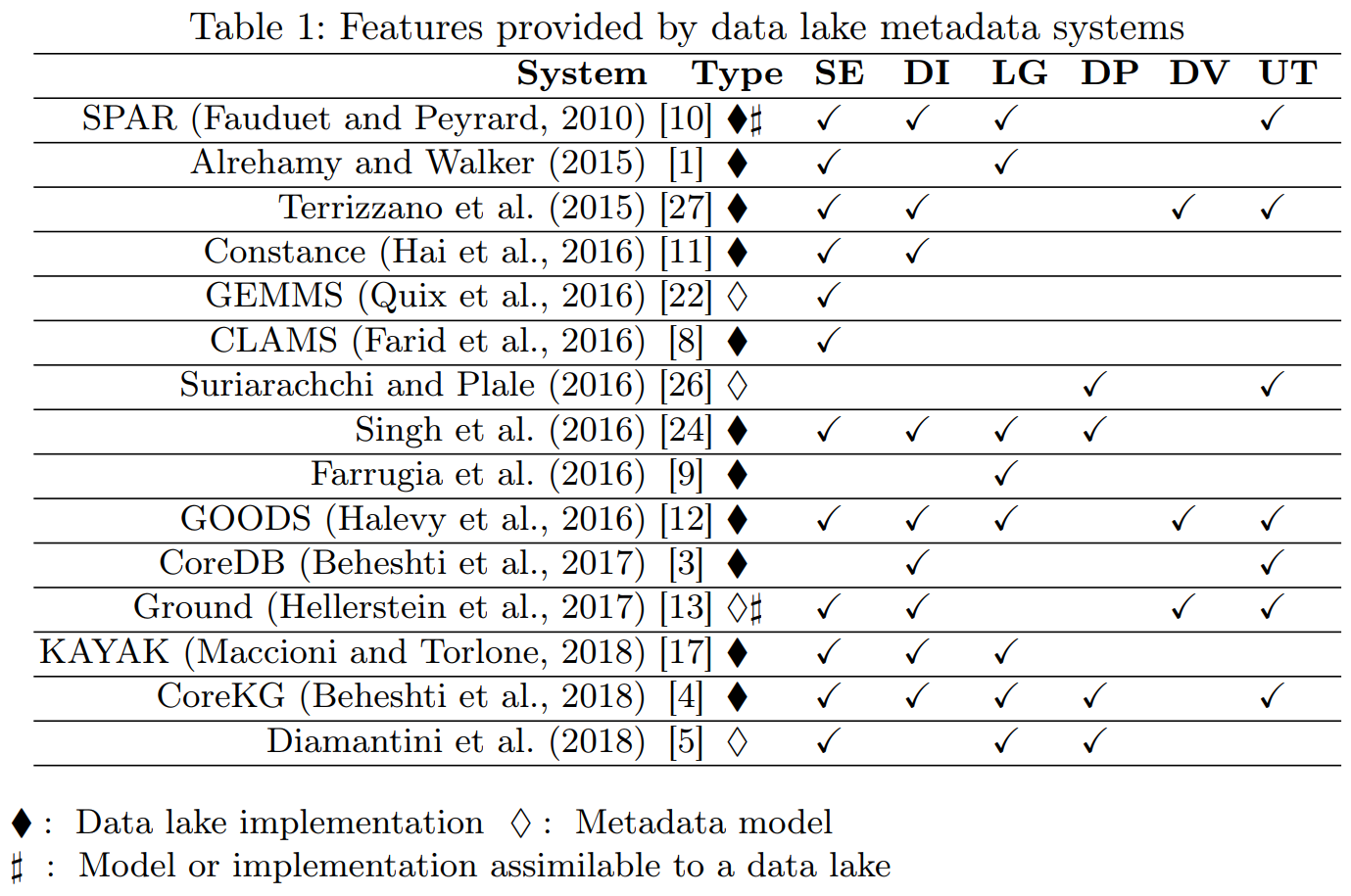
Semantic enrichment
- Add contextual descriptions (e.g., tags) for easier interpretation.
Data indexing
- Use structures to retrieve datasets by characteristics like keywords.
Link generation and conservation
- Detect similarities or maintain links between datasets.
Data polymorphism
- Store multiple data versions to avoid repeated pre-processing.
Data versioning
- Track data changes while preserving previous states.
Usage tracking
- Record user interactions with the data.
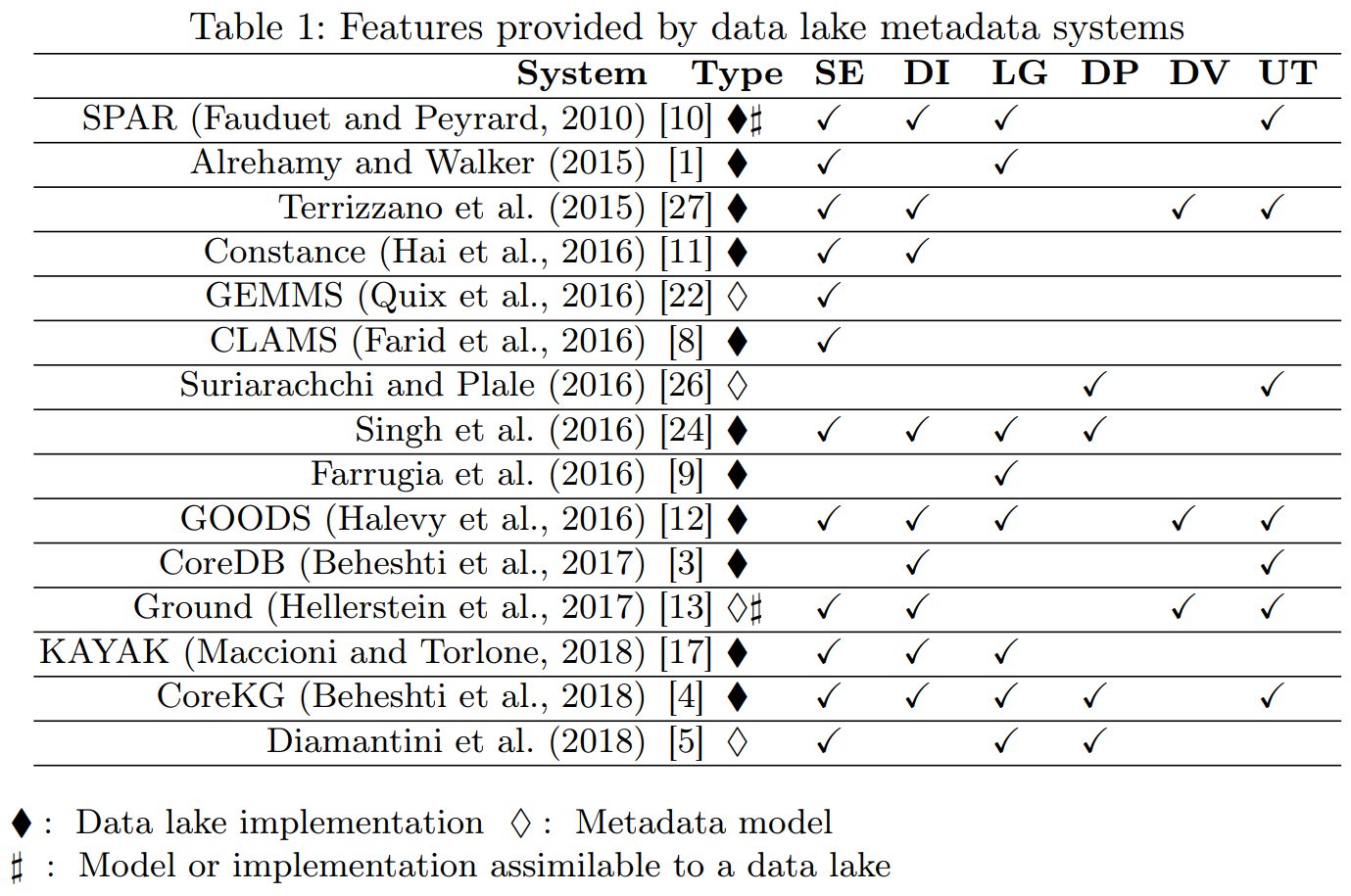
Constance: (Hai et al. 2016)
- Few details given on metamodel and functionalities.
- No metadata collected on operations.
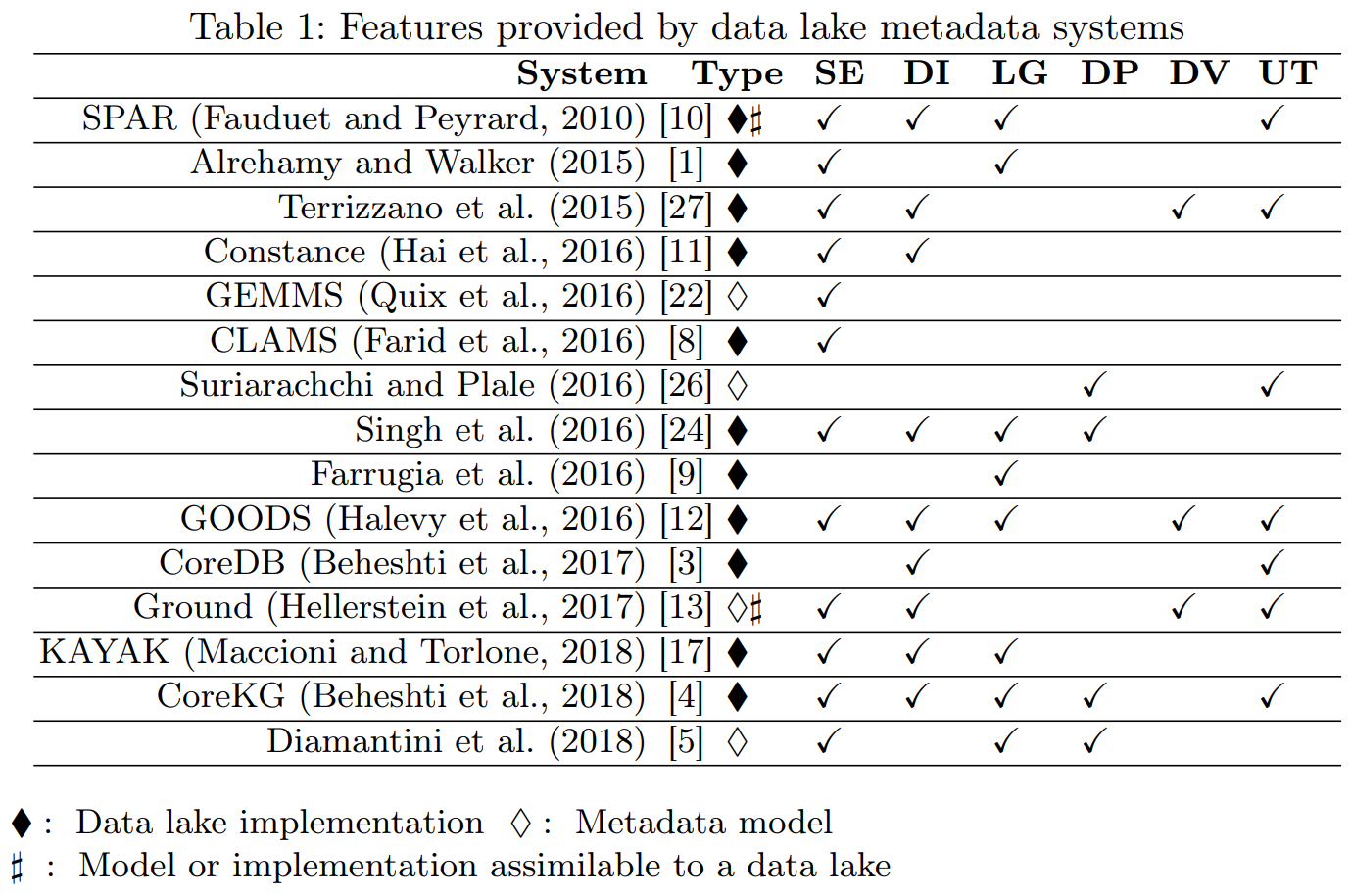
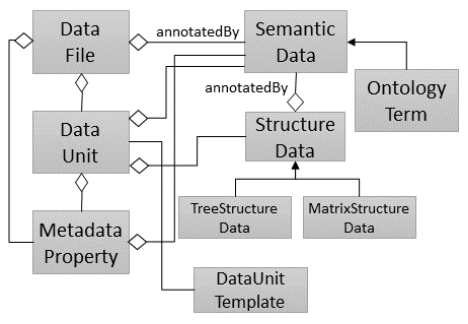
GEMMS: (Quix et al. 2016)
- No discussion about the functionalities provided.
- No metadata collected on operations and agents.
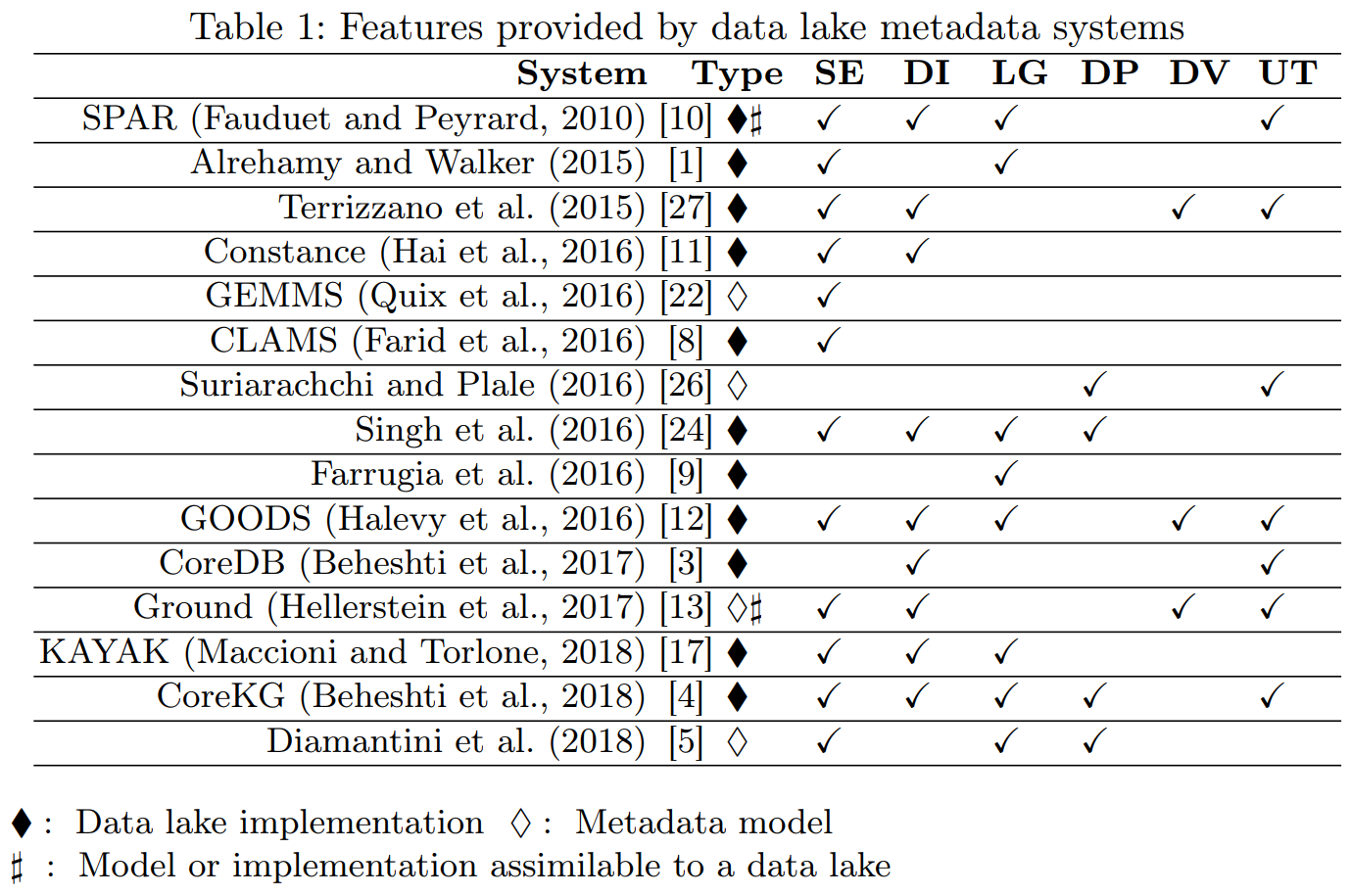
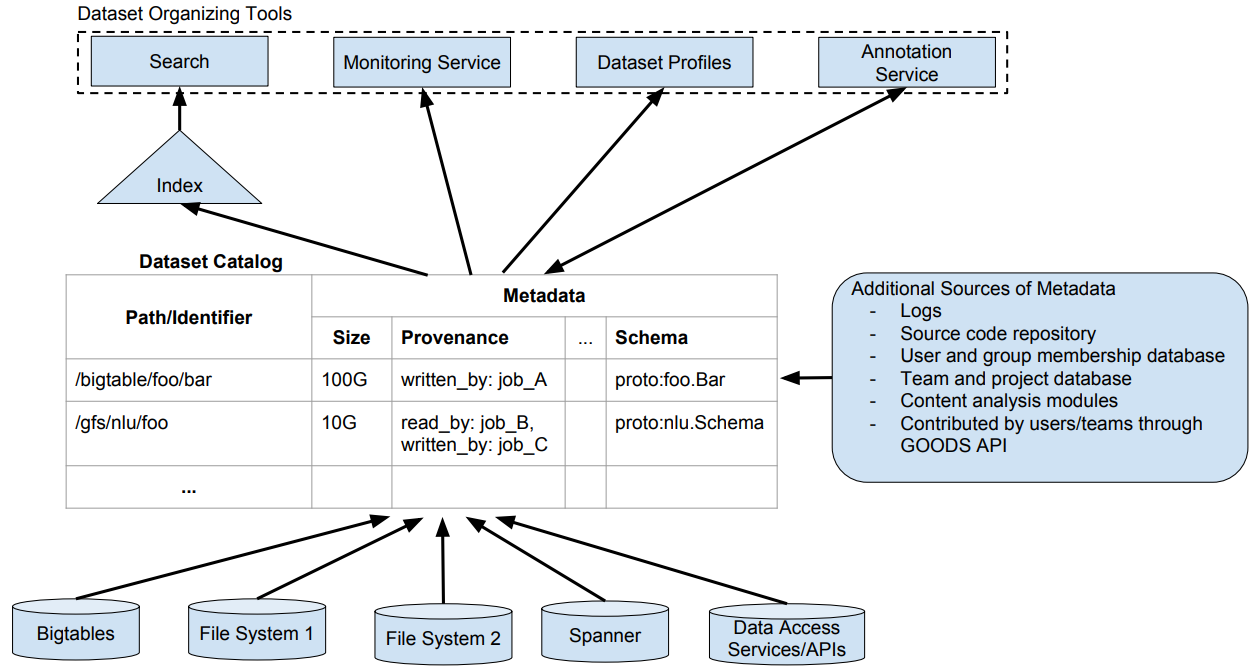
GOODS: (Halevy et al. 2016)
- Crawls Google’s storage systems to extract basic metadata on datasets and their relationship with other datasets.
- Performs metadata inference (e.g., determine the schema of a dataset, trace the provenance of data, or annotate data with their semantics).
- Strictly coupled with the Google platform.
- Mainly focuses on object description and searches.
- No formal description of the metamodel.
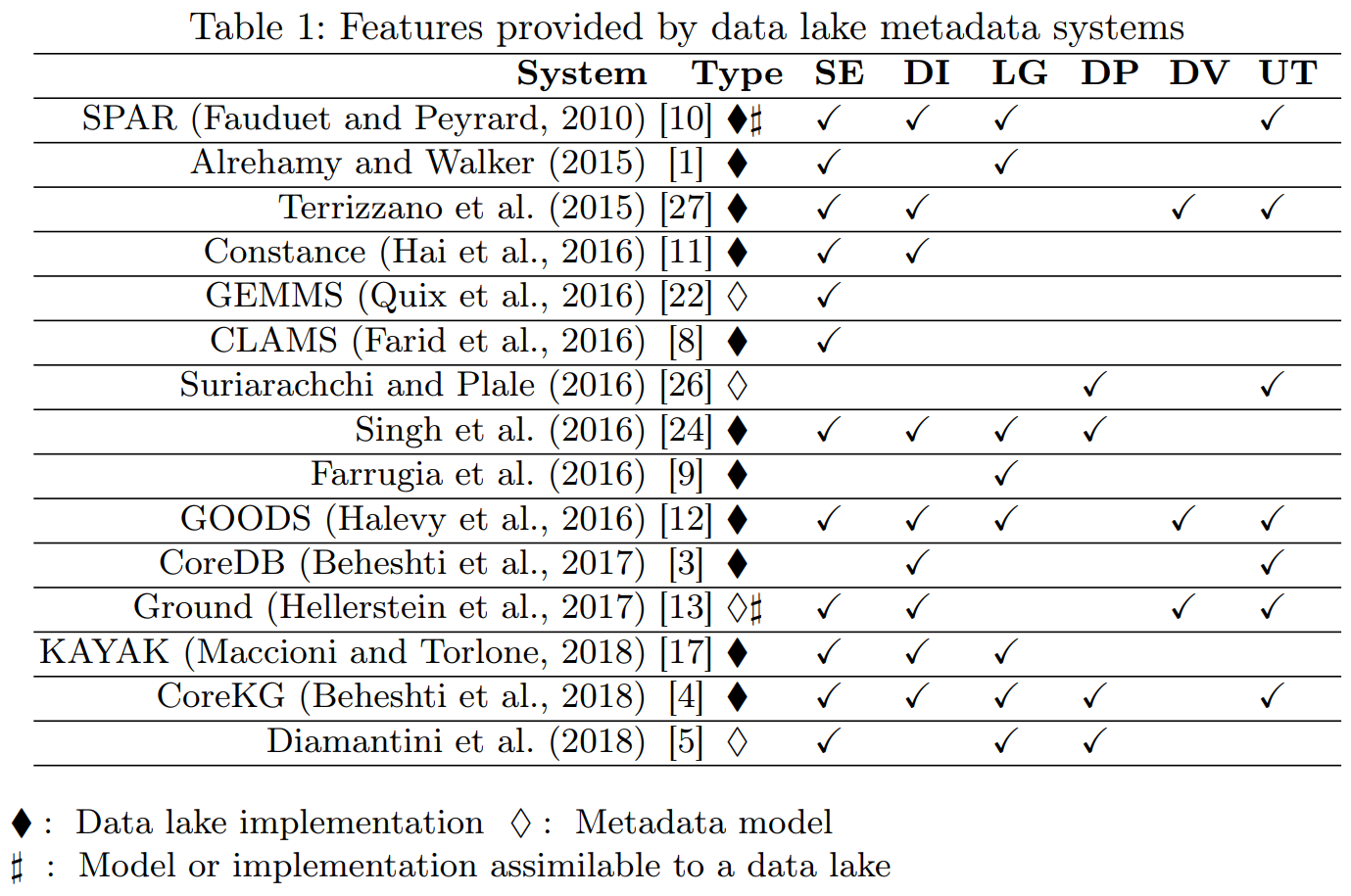
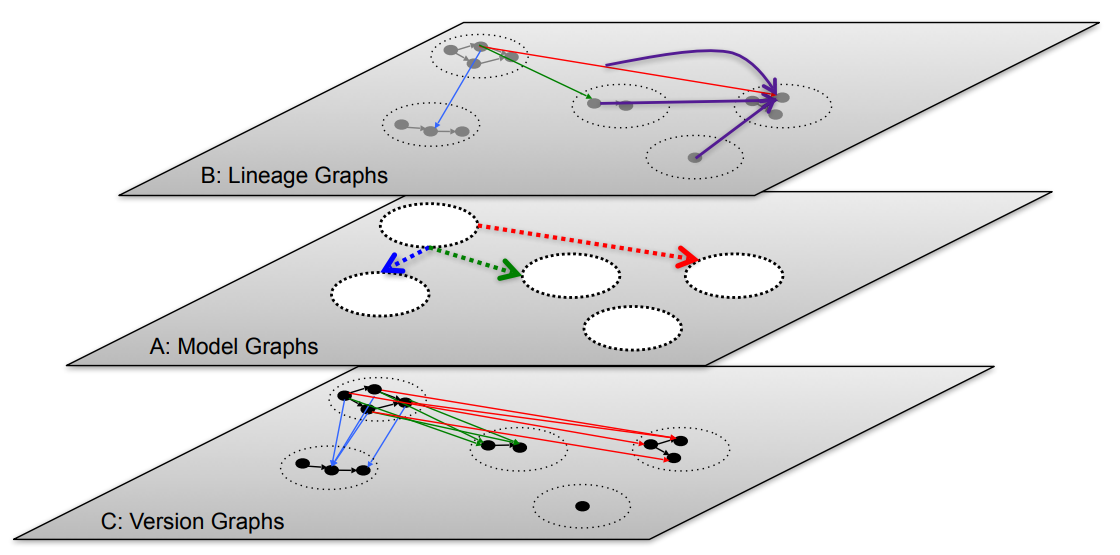
Ground: (Hellerstein et al. 2017)
- Version graphs represent data versions.
- Model graphs represent application metadata, i.e., how data are interpreted for use.
- Lineage graphs capture usage information.
- Not enough details given to clarify which metadata are actually handled.
- Functionalities are described at a high level.
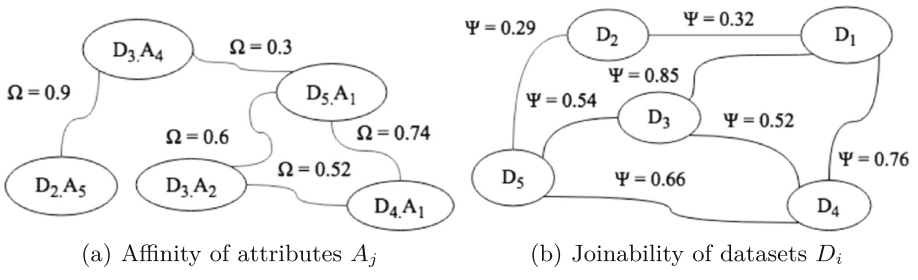
KAYAK: (Maccioni and Torlone 2018)
- Support users in creating and optimizing the data processing pipelines.
- Only goal-related metadata are collected.
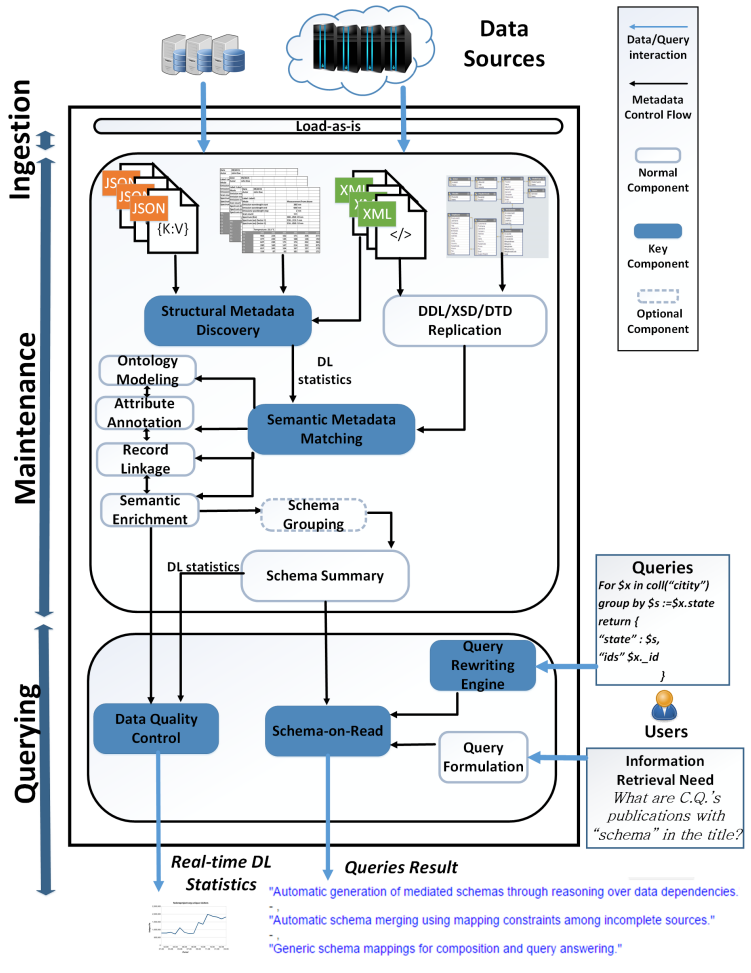
MOSES
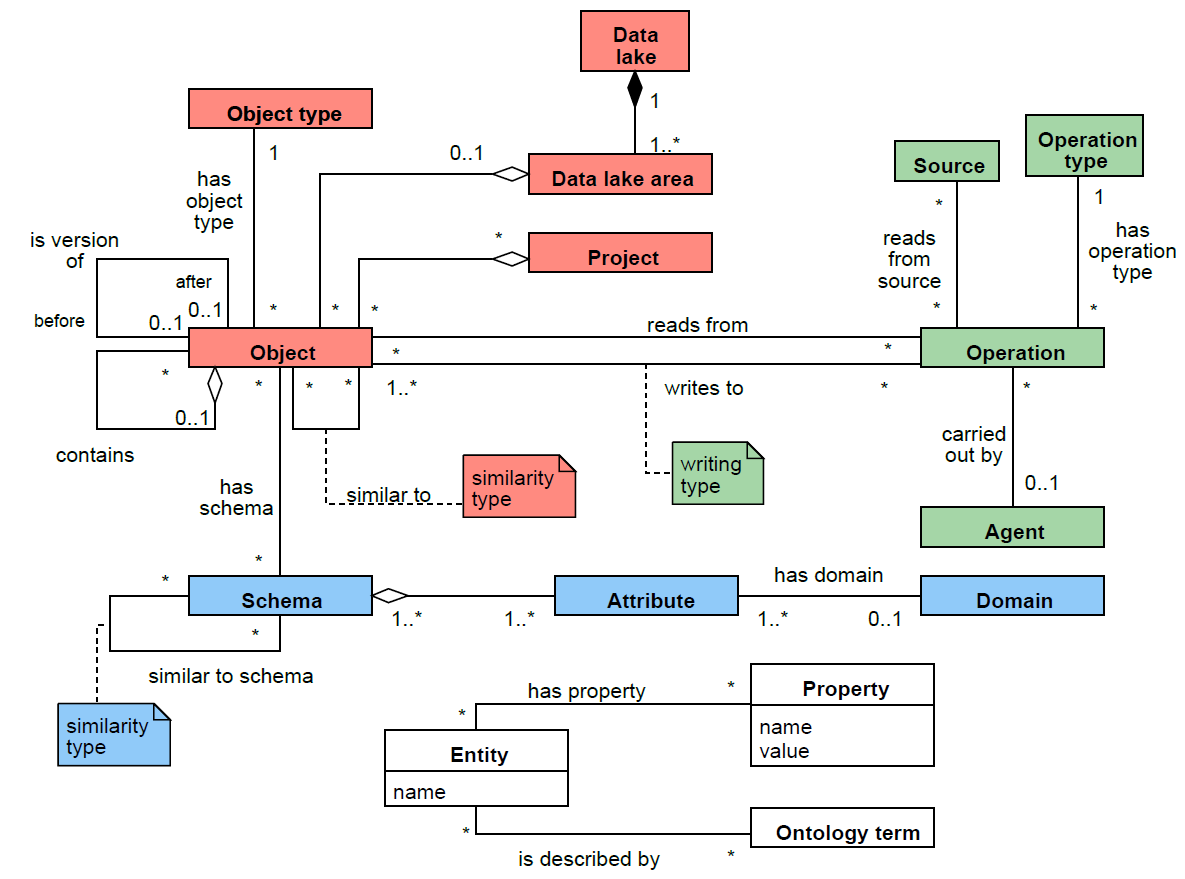
Three areas:
- Technical (blue)
- Operational (green)
- Business (red)
- Not pre-defined
- Domain-independent
- Extensible
Tune the trade-off between the level of detail of the functionalities and the required computational effort
MOSES: (Francia et al. 2021)
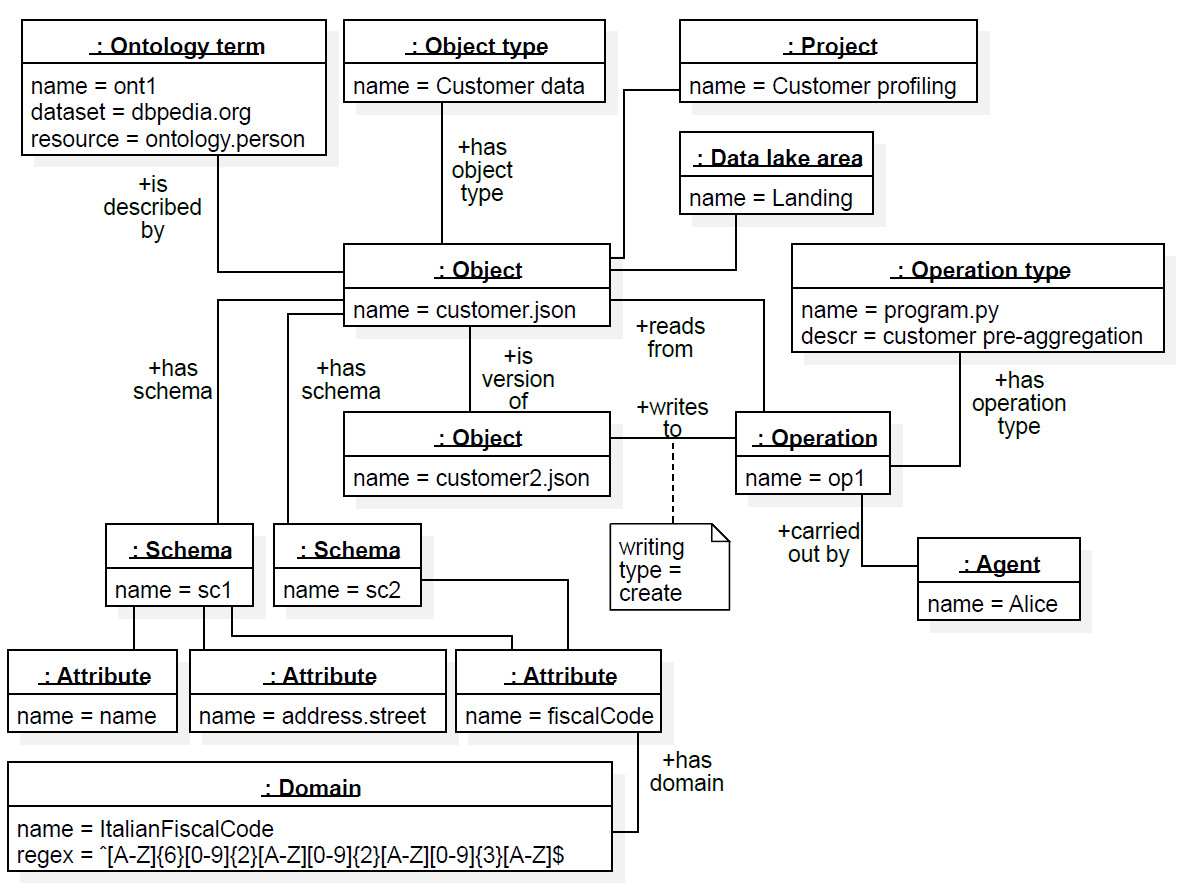
| Functionality | Supported |
|---|---|
| Semantic enrichment | Yes |
| Data indexing | No |
| Link generation | Yes |
| Data polymorphism | Yes |
| Data versioning | Yes |
| Usage tracking | Yes |
The Property Graph Data Model
Back in the database community
- Meant to be queried and processed
- THERE IS NO STANDARD!

R. Angles et al. Foundations of Modern Query Languages for Graph Databases
Example of Property Graph

Formal definition:
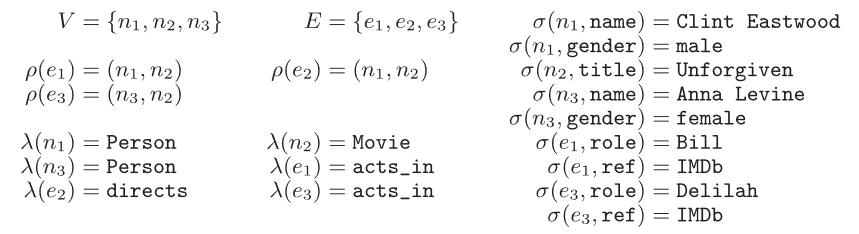
Return all objects of a given project
Return small objects with a given name pattern in the landing area
MATCH (o:Object)-[]-(d:DataLakeArea)
WHERE d.name = "Landing" AND o.name LIKE "2021_%"AND o.size < 100000
RETURN oSchema-driven search: return objects that contain information referring to a given Domain
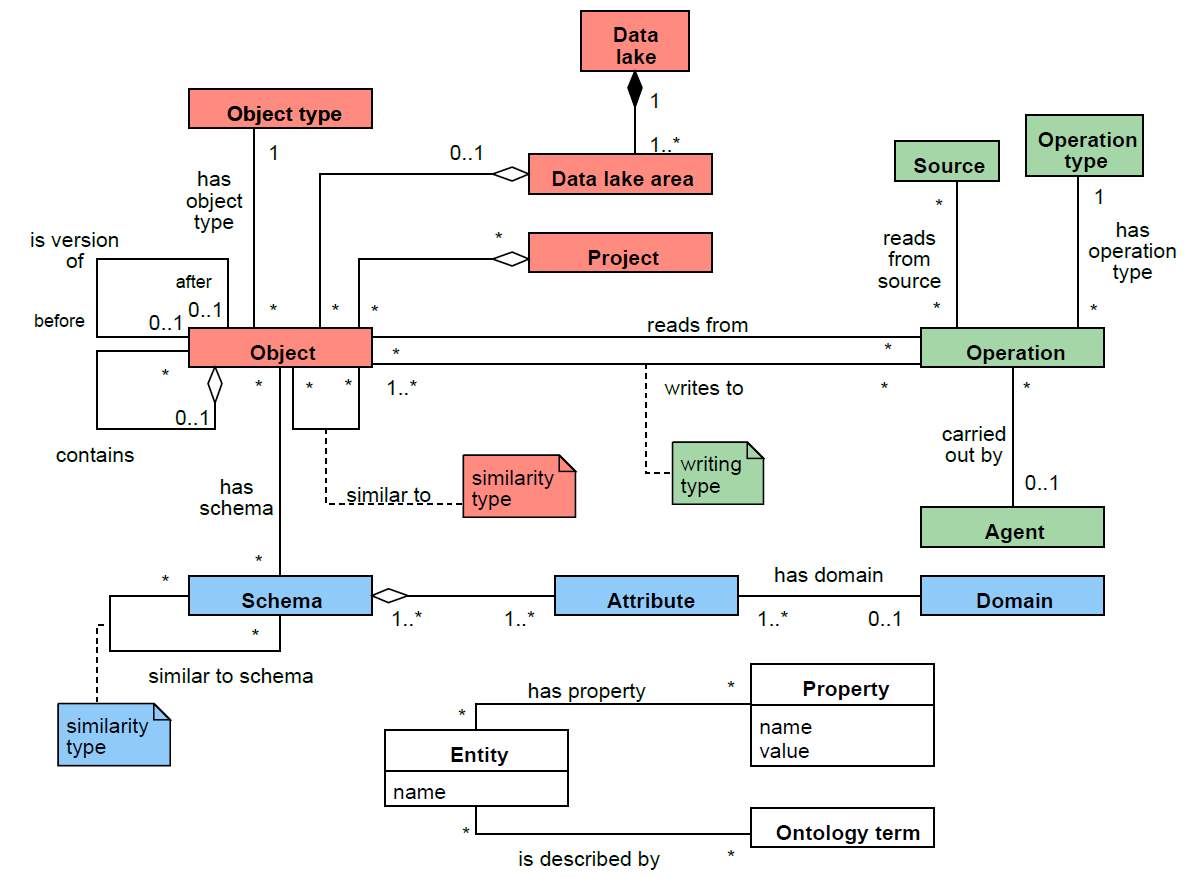
Provenance-driven search
MATCH (obj1:Object)-[:readsFrom]-(o:Operation)-[:writesTo]-(obj2:Object)
CREATE (obj1)-[:ancestorOf]->(obj2)Discover objects obtained from a given ancestor
Discover object(s) from which another has originated
Example: a ML team wants to use datasets that were publicized as canonical for certain domains, but they find these datasets being too “groomed” for ML
- Provenance links can be used to browse upstream and identify the less-groomed datasets that were used to derive the canonical datasets
Similarity-driven search
Discover datasets to be merged in a certain query
Discover datasets to be joined in a certain query
Group similar objects and enrich the search results
- List the main objects from each group
- Restrict the search to the objects of a single group
Semantics-driven search
Search objects without having any knowledge of theirphysical or intensional properties, but simply exploitingtheir traceability to a certain semantic concept
Profiling
MATCH (o:Object)-[]-(:OntologyType {name:"Table"}),
(o)-[]-(s:Schema)-[]-(a:Attribute),
(o)-[r:similarTo]-(o2:Object),
(o)-[:ancestorOf]-(o3:Object),
(o4:Object)-[:ancestorOf]-(o)
RETURN o, s, a, r, o2, o3, o4- Shows an object’s properties, list the relationships with other objects in terms of similarity and provenance
- Compute a representation of the intensional features that mostly characterize a group of objects(see slides on schema heterogeneity)